This is the multi-page printable view of this section. Click here to print.
Documentação
- 1: Visão geral
- 2: Primeiros passos
- 2.1: Primeira vez?
- 2.2: Instalação padrão
- 2.3: Instalação com Docker
- 2.4: Instalação com Nginx
- 2.5: Personalizar a instalação
- 2.6: Atualizar OpenDataBio
- 3: Serviços de API
- 3.1: Referência rápida
- 3.2: Obter dados - GET
- 3.3: Inserir dados - POST
- 3.4: Atualizar dados - PUT
- 4: Modelo conceitual
- 4.1: Objetos Centrais
- 4.2: Objetos de Atributos
- 4.3: Objetos de Acesso
- 4.4: Objetos Auxiliares
- 5: Como contribuir
- 6: Tutoriais
- 6.1: Obter dados via R
- 6.2: Importar dados via R
- 6.2.1: Importar Localidades
- 6.2.2: Importar BibReferences
- 6.2.3: Importar Vernacular
- 6.2.4: Importar Media
- 6.2.5: Importar Taxons
- 6.2.6: Importar Pessoas
- 6.2.7: Importar Variáveis
- 6.2.8: Importar Indivíduos & Vouchers
- 6.2.9: Importar Medições
1 - Visão geral
OpenDataBio é uma plataforma-web de código aberto projetada para ajudar pesquisadores e organizações que estudam a biodiversidade em regiões tropicais a coletar, armazenar, relacionar e servir dados. Ele é projetado para acomodar muitos tipos de dados usados em ciências biológicas e suas relações, particularmente para estudos de ecologia e biodiversidade e serve como um repositório de dados que permite a usuários baixar ou solicitar dados de pesquisa bem organizados e documentados.
Porque?
Estudos de biodiversidade freqüentemente requerem a integração de uma grande quantidade de dados, exigindo padronização para uso e compartilhamento. Pesquisadores também precisam gerenciar e manter os seus dados de forma contínua e para além de depositá-los de forma estática em repositórios públicos ou data papers.
O OpenDataBio foi desenhado com base na necessidade de organizar e integrar dados históricos e atuais coletados na região amazônica, levando em consideração as práticas de campo e os tipos de dados utilizados por ecologistas e taxonomistas.
O OpenDataBio visa facilitar a padronização e normalização dos dados, utilizando diferentes serviços disponíveis online, dando flexibilidade aos usuários e grupos de usuários, e criando os links necessários entre Localidades, Táxons, Indivíduos, Vouchers e as Medições e os Arquivos de Mídia associados a eles, ao mesmo tempo em que oferece acessibilidade aos dados por meio de um serviço de API próprio, facilitando a distribuição e análise dos dados.
Características relevantes
- Variáveis personalizadas - flexibilidade para o usuário definir variáveis incluindo casos especiais como variáveis Espectrais, Cores, Links e GeneBank. Essas variáveis são compartilhadas entre usuários e exigem metadados. Medições para tais características podem ser registradas para Indivíduos, Vouchers, Taxons ou Localidades.
- Taxons podem ser nomes publicados ou não publicados (por exemplo, um morfotipo), sinônimos ou nomes válidos e qualquer nó da árvore da vida pode ser armazenado. A inserção de táxons é verificada em diferentes bases nomenclaturais (Tropicos, IPNI, MycoBank, ZOOBANK, GBIF), minimizando busca por erros ortográficos, autores e sinônimos.
- Localidades são armazenadas com suas geometrias espaciais, permitindo consultas espaciais. Localidades como Parcelas e Transectos podem ser definidas, facilitando a organização de dados de métodos usados em estudos de biodiversidade.
- Controle de acesso e versionamento - os dados são organizados em Conjuntos de dados com política de acesso (público, restrito, projeto) e licença. Versões estáticas com filtros e citações próprias podem ser publicadas e baixadas.
- Diferentes grupos de pesquisa podem usar uma única instalação OpenDataBio, tendo controle sobre edição e acesso de seus dados particulares, enquanto compartilham bibliotecas comuns como Taxonomia, Localidades, Referências bibliográficas e Variáveis.
- Interface moderna - formulários, listas e buscas foram migrados para Livewire 3 + Alpine; antigas bibliotecas como DataTables, laravel-multiselect e autocompletes legados foram removidas em favor de componentes reativos.
- API para acessar dados programaticamente - Ferramentas para exportação e importação de dados são fornecidas por meio de serviços de API junto com um cliente API em R, o pacote OpenDataBio-R.
- Auditoria - o modelo de atividade audita alterações em qualquer registro e downloads de conjuntos de dados completos.
- O modelo BioColeção permite que uma Coleção Biológica gerencie seus registros de Vouchers e solicitações realizados por usuários.
- Coleta móvel com o aplicativo Android OpenDataBio Collect, sincronizando formulários configuráveis e dados de campo online/offline.
Saiba mais
- Primeiros passos: instale o OpenDataBio
2 - Primeiros passos
OpenDataBio é um web-software para Linux nas distribuições Debian, Ubuntu e Arch-Linux e pode ser implementado em qualquer máquina baseada em Linux. Não temos planos de suporte ao Windows, mas pode ser fácil de instalar em uma máquina Windows usando o Docker.
OpenDataBio é escrito em PHP e desenvolvido com o framework Laravel. Requer um servidor web (Apache ou nginx), PHP e um banco de dados SQL - testado apenas com MySQL e MariaDB .
Você pode instalar o OpenDataBio facilmente usando os arquivos Docker incluídos na distribuição. O repositório agora inclui o perfil docker/prod e o arquivo docker-compose.prod.yml, permitindo uso com Docker também em produção (com ajustes de infraestrutura e segredos).
Se você deseja testar o OpenDataBio, ajudar no desenvolvimento ou ter uma instalação individual no seu computador, siga a instalação do Docker.
Proximos passos
Prepare para instalação
- Você pode solicitar uma chave API Tropicos.org para que o OpenDataBio possa recuperar dados taxonômicos do banco de dados Tropicos.org. Se não for fornecido, principalmente o serviço de nomenclatura do GBIF será usado;
- OpenDataBio envia e-mails para usuários registrados, seja para informar sobre um job que foi concluído, para enviar solicitações de dados para administradores de Conjuntos de Dados, ou para recuperação de senha. Você pode usar um e-mail do Google para isso, mas precisará alterar as opções de segurança da conta para permitir que o OpenDataBio use a conta para enviar e-mails (você precisa ativar a opção de
Acesso a aplicativos menos segurosnas configurações da conta do gmail). Portanto, crie um endereço de e-mail dedicado para sua instalação. Verifique o arquivo “config/mail.php” para mais opções sobre como enviar e-mails.
2.1 - Primeira vez?
OpenDataBio é um software para ser instalado num servidor e acessível online. Você pode instalar localmente no seu computador como ambiente de desenvolvimento ou para seu uso pessoal. A instalação via Docker facilita a instalação do aplicativo.
Tipos de usuário
Se você se registrou, alguém precisa atribuir você como usuário pleno para que você possa inserir dados.
- Se você estiver instalando, o primeiro login para uma instalação do OpenDataBio deve ser feito com o usuário super-administrador padrão:
admin@example.orgepassword1. Essas configurações devem ser alteradas, senão a instalação fica aberta à qualquer pessoa lendo estas instruções. - Quando um usuário se auto-cadastra numa instalação do OpenDataBio, ele não tem permissão de edição ou inserção de dados, ele apenas ganha um cadastro e acesso aos conjuntos de dadosabertos para
usuários registradose permite que o usuário faça downloads, os quais exigem login. - Usuário pleno pode contribuir com dados
- Apenas super-administradores podem atribuir o papel de
usuário plenopara usuários registrados - diferentes instalações do OpenDataBio podem ter políticas diferentes sobre como você pode obter acesso de usuário pleno.
Ver mais em Usuários.
Prepare seu perfil de usuário-completo
- Criar um registro de Pessoa para você, e ligar ele como sua
pessoa padrãono seu perfil de usuário. Assim, os formulários da interface utilizarão essa Pessoa facilitando a entrada de dados. - Você precisará de pelo menos 1 conjunto de dados para entrar seus dados
- isso não é necessário para importar dados de bibliotecas compartilhadas, como Pessoas, Localidades, Taxons e Referências Bibliográficas).
- Você poderá criar tantos projetos e conjuntos de dados que precisar. Entenda bem esses Objetos de Controle de Acesso do OpenDataBio.
Entrando e editando dados
Existem várias maneiras entrar e editar dados no OpenDataBio:
- Registro por registro por meio da interface web, com ajuda de serviços de API para taxons e referências bibliográficas.
- Através de Formulários via interface Web, onde você pode entrar Medições.
- Através do aplicativo para Android ODBCollect, para o qual você pode criar diferentes tipos de Formulários ODBCollect e usar para coletar dados offline e enviar diretamente para o banco de dados.
- Usando a Application Programming Interface -API do OpenDataBio, que facilita o processamenta de dados em lote (batch):
- importar dados de arquivos CSV, XLXS ou ODS usando a interface (Menu Importar)
- através do R, usando o pacote OpenDataBio R, que é um cliente para essa API.
- criando o seu próprio cliente em outra linguagem
- Ao usar os serviços da API OpenDataBio você deve preparar seus dados ou arquivo para importação e atualização de acordo com as opções de campo dos verbos POST e PUT para o
endpointespecífico que você está tentando importar. Verifique também a referência rápida da API.
Veja os tutoriais para exemplos de como usar o pacote do R e a API para obter e importar dados.
Dicas para inserir dados
- Se for inserir dados pela primeira vez, recomendamos que você utilize a interface pelo seu navegador e crie pelo menos um registro para cada objeto que atenda às suas necessidades. Em seguida, experimente as configurações de privacidade do seu espaço de trabalho conjunto de dados e verifique se você pode acessar os dados quando estiver conectado ou não. Ou seja, entenda como os dados ficam organizados e veja como obtê-los.
- Use Conjunto de dados para um conjunto independente de dados que deve ser distribuído como um grupo. Os conjuntos de dados são publicações dinâmicas, têm autor, dados e título e versões estáticas podem ser geradas, facilitando o download e a distribuição.
- Embora o ODB tente minimizar a redundância, dar flexibilidade aos usuários tem um custo em algumas definições, como por exemplo, Variáveis e [Pessoas](/docs/concepts/objetos auxiliares/#person) que podem receber registros duplicados. Portanto, deve-se ter cuidado ao criar tais registros. Os administradores podem criar um código de conduta para os usuários de uma instalação ODB para minimizar tal redundância, customizando a instalação.
- Siga uma ordem de importação de novos dados a partir das bibliotecas de uso comum. Por exemplo, você deve primeiro registrar Taxons, Pessoas, Variáveis e qualquer outra biblioteca comum antes de importar Indivíduos ou Medições. Localidades podem ou não ser necessário importar antes. Se for apenas coordenada geográfica não é necessário.
- OpenDataBio pode ser instalado com dados previamente organizados para algumas Localidades, unidades administrativas, Município, Estado, País, Unidades de Conservação Federais e Terras Indígenas, e uma base da árvore da vida para Taxons complementada pela filogenia das plantas com sementes até o nível de Ordem conforme a árvore do Angiosperm Phylogeny WebSite.
- Não há nenhuma necessidade de importar localidades do tipo
POINTpara importar Indivíduos porque o ODB cria a localidade para você se informar latitude e longitude, e detectará para você a qual são as localidades registradas à qual o indivíduo pertence. Ou seja, ODB detecta as unidades administrativas (Município, Estados, Pais), as Unidades de Conservação e Terras Indígenas e também classes ambientais, dependendo das Localidades registradas na base de dados. Você pode usar a API de validação de localidades para validar previamente as coordenadas. - Existem diferentes maneiras de criar localidades do tipo PARCELA e TRANSECTOS - saiba mais em Localidades.
- A criação de taxons exige apenas a especificação de um
nome- ODB pesquisará os serviços de nomenclatura para você, encontrará o nome, metadados e taxons pais ou taxons aceitos, se o seu nome for um sinônimo, e importará todos os eles. Se necessário até encontrar na base algum taxon na hierarquia ancestral. Por exemplo, se informar Ocotea guianensis, mas apenas a ordem Laurales estiver cadastrada na base, ODB irá buscar e cadastrar para você todo o caminhoLauraceae >> Ocotea >> Ocotea guianensis, com autoria, referencia bibliográfica e link ao repositório nomenclatural onde encontrou os dados. Se você estiver importando nomes publicados, basta informar este único atributo. Se o nome taxonômico não for publicado é necessário informar campos adicionais. Portanto, separe a importação em lote de nomes publicados e não publicados em dois conjuntos. - O campo
notesde qualquer modelo é para texto simples ou para dados formatados como objectos JSON. A opção Json permite que você armazene dados estruturados personalizados em qualquer modelo que tenha o camponotes. Você pode, por exemplo, armazenar como notas alguns campos secundários de fontes originais ao importar dados, mas pode armazenar quaisquer dados adicionais que não sejam fornecidos pela estrutura do banco de dados do OpenDataBio. Esses dados não serão validados pelo OpenDataBio e a padronização depende de você. As notas Json serão importadas e exportadas como um texto JSON e serão apresentadas na interface como uma tabela formatada; URLs em seu Json serão apresentados como links.
2.2 - Instalação padrão
Estas instruções são para instalação baseada em apache. Para nginx, use Instalação com Nginx.
Requisitos do servidor
- A versão suportada do PHP >= 8.2 (8.3 recomendado).
- Servidor web: apache para este guia. Para nginx, use Instalação com Nginx.
- Requer um banco de dados SQL, MySQL e MariaDB foram testados, mas também pode funcionar com Postgres. Testado com MySQL 8.0 e MariaDB 10.6+.
- Extensões PHP necessárias:
openssl,pdo,pdo_mysql,mbstring,tokenizer,xml,dom,gd,exif,bcmath,zip,curl,redis. - Redis Server é necessário para filas e cache.
- Tectonic é usado para geração de PDFs/etiquetas a partir de LaTeX.
- Pandoc é usado para traduzir o código LaTeX usado nas referências bibliográficas. Não é necessário para a instalação, mas é sugerido para uma melhor experiência do usuário.
- Requer Supervisor, que é necessário para os jobs de usuário
Criar usuário dedicado
A maneira recomendada de instalar o OpenDataBio para produção é usando um usuário de sistema dedicado. Nestas instruções, esse usuário é odbserver.
Baixar OpenDataBio
Faça login como seu Usuário dedicado e baixe ou clone este software para onde deseja instalá-lo.
Aqui assumimos que é /home/odbserver/opendatabio para que os arquivos de instalação residam neste diretório. Se este não for o seu caminho, altere abaixo sempre que aplicável.
Baixar OpenDataBio
Prepare o Servidor
Primeiro, instale os softwares Apache, MySQL, PHP, Redis, Tectonic, Pandoc e Supervisor. Em um sistema Debian, você também precisa instalar algumas extensões PHP e ativá-las:
#EXEMPLO EM UBUNTU 22.04
#repositórios
apt-get install software-properties-common
add-apt-repository ppa:ondrej/php
add-apt-repository ppa:ondrej/php ppa:ondrej/apache2
add-apt-repository ppa:ondrej/php
add-apt-repository ppa:ondrej/apache2
apt update
#instala o php
apt install php8.3 -y
apt update
apt upgrade
#instala extensoes (modulos) do php
php --version
#quais os modulos instalados?
php -m
#se algum desses nao estive, instale
apt install php8.3-{bcmath,xml,mysql,zip,intl,gd,cli,curl,mbstring,sqlite3,redis}
#install apache
apt install libapache2-mod-php8.3
#instala redis e tectonic
apt install redis-server tectonic
#install pandoc
apt install pandoc
#install supervisor (needed for jobs)
apt-get install supervisor -y
a2enmod php8.3
phpenmod mbstring
phpenmod xml
phpenmod dom
phpenmod gd
a2enmod rewrite
a2ensite
systemctl restart apache2.service
#To check if they are installed:
php -m | grep -E 'mbstring|cli|xml|gd|mysql|redis|bcmath|pcntl|zip'
tectonic --version
redis-server --version
Adicione o seguinte à sua configuração do Apache.
- Mude
/home/odbserver/opendatabiopara o seu caminho (os arquivos devem estar acessíveis pelo apache) - Você pode criar um novo arquivo na pasta sites-available:
/etc/apache2/sites-available/opendatabio.confe colocar o seguinte código nele.
<IfModule alias_module>
Alias /opendatabio /home/odbserver/opendatabio/public/
Alias /fonts /home/odbserver/opendatabio/public/fonts
Alias /images /home/odbserver/opendatabio/public/images
Alias /build /home/odbserver/opendatabio/public/build
Alias /vendor/livewire /home/odbserver/opendatabio/public/vendor/livewire
<Directory "/home/odbserver/opendatabio/public">
Require all granted
AllowOverride All
</Directory>
</IfModule>
Isso fará com que o Apache redirecione todas as solicitações de / para a pasta correta, e também permitirá que o arquivo .htaccess fornecido controle as regras de reescrita, de forma que os URLs sejam bonitos. Se desejar acessar o arquivo apontando o navegador para a raiz do servidor, adicione também a seguinte diretiva:
RedirectMatch ^/$ /
Content Security Policy (CSP) para Apache
Configure o CSP na camada do servidor web (não nos arquivos Laravel). Aplique primeiro em modo report-only, valide os logs e depois migre para enforcement.
Para instalação standalone com nginx, use Instalação com Nginx.
Apache: onde colocar
- Habilite o módulo necessário:
sudo a2enmod headers
sudo systemctl restart apache2
- Edite o arquivo de vhost ativo (exemplo):
sudo nano /etc/apache2/sites-available/opendatabio.conf
- Dentro do bloco
<VirtualHost ...>correto (HTTP e/ou HTTPS), adicione:
Header always set Content-Security-Policy-Report-Only "
default-src 'self';
base-uri 'self';
form-action 'self';
frame-ancestors 'self';
object-src 'none';
script-src 'self' 'unsafe-eval';
style-src 'self' 'unsafe-inline';
img-src 'self' data: https://server.arcgisonline.com https://*.tile.openstreetmap.org;
font-src 'self' data:;
connect-src 'self';
"
- Recarregue o Apache:
sudo apachectl configtest
sudo systemctl reload apache2
Instalações em subcaminho (/opendatabio)
Se sua instalação roda em subcaminho (por exemplo http://localhost/opendatabio), ajuste no .env:
APP_URL=http://localhost/opendatabio
ASSET_URL=http://localhost/opendatabio
Depois atualize os assets gerados e arquivos do Livewire:
php artisan livewire:publish --assets
php artisan optimize:clear
npm run build
Notas
https://server.arcgisonline.comehttps://*.tile.openstreetmap.orgsão necessários para tiles do mapa.unsafe-inline/unsafe-evalsão flags temporárias de compatibilidade; remova após endurecer templates/assets.- Mantenha
Report-Onlyenquanto ajusta a política em produção.
Configure seu arquivo php.ini. O instalador pode reclamar da falta de extensões do PHP, então lembre-se de ativá-las nos arquivos cli (/etc/php/8.3/cli/php.ini e web ini (/etc/php/8.3/fpm/php.ini) para PHP!
Atualize os valores para as seguintes variáveis:
Encontre os arquivos
php -i | grep 'Configuration File'
Mudar:
memory_limit should be at least 512M
post_max_size should be at least 30M
upload_max_filesize should be at least 30M
Algo como:
[PHP]
allow_url_fopen=1
memory_limit = 512M
post_max_size = 100M
upload_max_filesize = 100M
Habilite os módulos Apache ‘mod_rewrite’ e ‘mod_alias’ e reinicie o servidor:
sudo a2enmod rewrite
sudo a2ensite
sudo systemctl restart apache2.service
Mysql Charset e Collation
- Você deve adicionar o seguinte ao seu arquivo de configuração do SQL (mariadb.cnf ou my.cnf), ou seja, o conjunto de caracteres e o agrupamento que você escolher para sua instalação devem corresponder aos do
config/database.php
[mysqld]
character-set-client-handshake = FALSE #without this, there is no effect of the init_connect
collation-server = utf8mb4_unicode_ci
init-connect = "SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci"
character-set-server = utf8mb4
log-bin-trust-function-creators = 1
sort_buffer_size = 256M #espaco suficiente para consultas com geometria
[mariadb]
max_allowed_packet=100M
innodb_log_file_size=300M #no use for mysql
- Se estiver usando MariaDB e você ainda tiver problemas do tipo #1267 Illegal mix of collations, então verifique aqui sobre como consertar isso.
Configurar o supervisord
Configure o Supervisor, que é necessário para trabalhos. Crie um nome de arquivo opendatabio-worker.conf na pasta de configuração do Supervisor /etc/supervisor/ conf.d/opendatabio-worker.conf com o seguinte conteúdo, ajustando o caminho conforme a sua instalação:
touch /etc/supervisor/conf.d/opendatabio-worker.conf
echo ";--------------
[program:opendatabio-worker]
process_name=%(program_name)s_%(process_num)02d
command=php /home/odbserver/opendatabio/artisan queue:work --sleep=3 --tries=1 --timeout=0 --memory=512
autostart=true
autorestart=true
user=odbserver
numprocs=8
redirect_stderr=true
stdout_logfile=/home/odbserver/opendatabio/storage/logs/supervisor.log
;--------------" > /etc/supervisor/conf.d/opendatabio-worker.conf
Permissões de arquivos e pastas
As permissões de pasta e arquivo são importantes para proteger a instalação em um servidor aberto publicamente. Se você não configurar corretamente, seu site poderá estar em risco.
- As pastas
storageebootstrap/cacheprecisam ter permissão de escrita para o usuário do servidor (geralmente www-data). Defina0775para esses diretórios. - O arquivo de configuração
.envprecisa ter permissão0640pois contém senhas. - Este link mostra diferentes métodos de definir permissões para um aplicativo Laravel.
Este é o método recomendado:
cd /home/odbserver
#note que odbserver e www-data podem mudar na sua configuracao
#defia as permissões tanto par ao seu usuário (aqui odbserver) como para o do apache (aqui www-data)
sudo chown -R odbserver:www-data opendatabio
sudo find ./opendatabio -type f -exec chmod 644 {} \;
sudo find ./opendatabio -type d -exec chmod 755 {} \;
cd /home/odbserver/opendatabio
sudo chgrp -R www-data storage bootstrap/cache
sudo chmod -R ug+rwx storage bootstrap/cache
#pasta media ajustar
sudo find ./storage/app/public/media -type f -exec chmod 664 {} \;
sudo find ./storage/app/public/media -type d -exec chmod 775 {} \;
#arquivo de configuracao .env para permissao 640
sudo chmod 640 ./.env
Instale OpenDataBio
Muitas distribuições Linux (Ubuntu e Debian) têm arquivos php.ini diferentes para a interface de linha de comando e para o Apache. Recomenda-se usar o arquivo de configuração do Apache ao executar o script de instalação, para que ele possa apontar corretamente as extensões ou configurações ausentes. Para fazer isso, encontre o caminho correto para o arquivo .ini e exporte-o **antes de usar o comando de instalação
php install**.Por exemplo,
export PHPRC=/etc/php/8.3/apache2/php.iniO script de instalação baixará o gerenciador de dependências Composer e todas as bibliotecas PHP necessárias listadas no arquivo
composer.json. No entanto, se o seu servidor estiver atrás de um proxy, você deve instalar e configurar o Composer independentemente. Implementamos a configuração do PROXY, mas não a estamos mais usando e não testamos corretamente (se você precisar de ajustes, coloque um issue no GitLab).O script solicitará opções de configuração, que são armazenadas no arquivo de ambiente
.envna pasta raiz do aplicativo.Você pode, opcionalmente, configurar este arquivo antes de executar o instalador:
- Crie um arquivo
.envcom o conteúdo docp .env.example .envfornecido - Leia os comentários neste arquivo e ajuste de acordo
- Garanta que
ASSET_URLesteja correto para a URL/subcaminho da sua instalação
- Crie um arquivo
Execute o instalador:
cd /home/odbserver/opendatabio
php install
- Compile os assets frontend depois de configurar o
.env(obrigatorio quandoASSET_URLe adicionado ou alterado):
npm ci #talvez precise disso
npm run build
- Seed data - o script irá pergunar se você quer instalar Localidades e Taxons distribuídos com aplicativo. Esses dados são específicos de cada versão do OpenDataBio. Ver as notas das versões no repositório desses dados.
Se o script de instalação for concluído com sucesso, você está pronto para prosseguir! Aponte seu navegador para http://localhost/opendatabio. As migrações de banco de dados incluem uma conta de administrador, com login admin@example.org e senha password1. Altere a senha após a instalação.
Problemas de instalação
Existem inúmeras maneiras possíveis de instalar o aplicativo, mas podem envolver mais etapas e configurações.
- se o navegador retornar 500|SERVER ERROR , você deve olhar para o último error em
storage/logs/laravel.log. Se você tiver ERROR: No application encryption key has been specified execute:
chave artesanal php: gerar
php artisan config: cache
- Se você receber o erro failed to open stream: Connection timed out durante a execução do instalador, isso indica uma configuração incorreta do seu roteamento IPv6. A correção mais fácil é desabilitar o roteamento IPv6 no servidor.
- Se você receber erros durante alimentação aleatória do banco de dados, você pode tentar remover o banco de dados inteiramente e reconstruí-lo. Claro, não execute isso em uma instalação de produção.
php artisan migrate: fresh
- Você pode substituir as tabelas Locations e Taxons usando o seed data depois de reconstruir a base:
php seedodb
Configurações pós-instalação
- Se seus Jobs de importação/exportação não estão sendo processados, certifique-se de que o Supervisor esteja executando
systemctl start supervisord && systemctl enable supervisorde verifique os arquivos de log emstorage/logs/supervisor.log. - Você pode alterar várias variáveis de configuração para o aplicativo. O mais importante deles provavelmente está definido pelo instalador, mas há outras variáveis em
.enve no arquivoconfig/app.phpque você pode alterar. Em particular, você pode querer alterar as configurações de idioma, fuso horário e e-mail. Executephp artisan config: cacheapós atualizar os arquivos de configuração. - Para impedir que os rastreadores do mecanismo de pesquisa indexem seu banco de dados, adicione o seguinte ao seu “robots.txt” na pasta raiz do servidor (no Debian, /var/www/html):
User-agent: *
Disallow: /
- As pastas
storageebootstrap/cachedevem ser graváveis pelo usuário do Apache (geralmente www-data). Veja este link para um exemplo de como fazer isso. Defina a permissão0775para esses diretórios.
Atualizando uma instalação Apache existente
Antes de atualizar, faça backup do banco de dados, do arquivo .env e de storage/app/public/media.
Antes de rodar os comandos, revise diferencas de configuracao da versao alvo:
- Compare
.envcom.env.example(incluindoassets_url) - Confira configuracoes do PHP (
php.iniem CLI e FPM/Apache) - Confira configuracao dos workers no Supervisor
- Coloque a aplicação em modo de manutenção:
cd /home/odbserver/opendatabio
php artisan down
- Atualize o código-fonte para a versão desejada:
git fetch --tags
git checkout <tag-ou-branch-de-destino>
- Atualize dependências e aplique migrações de banco:
composer install --no-dev --optimize-autoloader
php artisan migrate --force
- Recompile os assets frontend apos mudancas no
.env:
npm run build
- Recrie os caches e reinicie os workers de fila:
php artisan optimize:clear
php artisan config:cache
php artisan queue:restart
- Tire a aplicação do modo de manutenção:
php artisan up
Se a versão de destino incluir novas variáveis de ambiente, adicione-as ao .env antes de rodar assets/cache. Veja o conteúdo de .env.example para mudanças necessárias.
Armazenamento e backups
Você pode alterar as configurações de armazenamento em config/filesystem.php, onde pode definir o armazenamento baseado em nuvem, que pode ser necessário se muitos usuários enviarem arquivos de mídia, exigindo muito espaço em disco.
- Downloads de dados são colocados em fila como Jobs e um arquivo é gravado em uma pasta temporária,sendo excluído quando o trabalho é excluído pelo usuário. Esta pasta é definida como
download diskno arquivo de configuração filesystem.php, que aponta parastorage/app/public/downloads. Apagar esses arquivos temporários depende dos usuários, portanto, um trabalho de limpeza do cron pode ser aconselhável para implementar em sua instalação; - Arquivos de mídia são armazenados por padrão no
media disk, que coloca os arquivos na pastastorage/app/ public/media; - Para configuração regular crie ambos os diretórios
storage/app/public/downloadsestorage/app/public/mediacom permissões graváveis pelo usuário do servidor - Lembre-se de incluir a pasta de mídia em um plano de backup;
2.3 - Instalação com Docker
A maneira mais fácil de instalar e executar o OpenDataBio é usando o Docker e os arquivos de configuração do docker fornecidos, que contêm todas as configurações necessárias para executar o ODB. Usa nginx e mysql e supervisor.
Por padrão, o fluxo rápido está otimizado para desenvolvimento e testes locais.
Perfil de produção
O OpenDataBio agora inclui um perfil Docker orientado a produção:
docker/prod/nginx.confdocker/prod/php.inidocker/prod/www.confdocker-compose.prod.yml
Execute o compose de produção com:
docker compose -f docker-compose.prod.yml build
docker compose -f docker-compose.prod.yml up -d
Principais diferenças em relação ao dev:
- Usa configurações nginx/php-fpm em
docker/prod/*. - Remove bind-mounts do código-fonte da aplicação.
- Desativa o phpMyAdmin por padrão (perfil
dev-only). - Publica o nginx na porta
80(ajuste se houver reverse proxy).
O CSP no nginx (report-only) está incluído em docker/prod/nginx.conf. Mantenha report-only primeiro e só depois aplique enforcement.
Arquivos Docker incluídos
laravel-app/
----docker/*
----.env.docker
----docker-compose.yml
----Dockerfile
----Makefile
Eles foram adaptados deste link, onde você também encontra uma configuração de produção.
Instalação
Baixar OpenDataBio
Pré-requisitos
- Docker com plugin Compose (
docker composev2). - Linux/mac: usuário no grupo docker ou usar
sudo. - Windows: Docker Desktop (WSL2/Hyper-V habilitados).
Início rápido (Linux/mac, requer make)
cd opendatabio
make docker-init # copia .env.docker se faltar, sobe containers, instala composer, gera key, migra e faz storage:link
make seed-odb # seed opcional para Locations/Taxons
#ou tudo junto
make docker-init SEED=1 # igual acima + seed opcional para Locations/Taxons
- Depois de configurar o
.env(ou sempre queASSET_URLmudar), recompile os assets:
npm run build
- App: http://localhost:8081 (usuário
admin@example.org/password1) - phpMyAdmin: http://localhost:8082
Windows (PowerShell)
cd opendatabio
powershell -ExecutionPolicy Bypass -File scripts/docker-init.ps1
# opcional seed
powershell -ExecutionPolicy Bypass -File scripts/docker-init.ps1 -Seed
Comandos manuais (se você não tiver make)
cp .env.docker .env
docker compose up -d
docker compose exec -T -u www-data laravel composer install --optimize-autoloader
docker compose exec -T -u www-data laravel php artisan key:generate --force
docker compose exec -T -u www-data laravel php artisan migrate --force
docker compose exec -T -u www-data laravel php artisan storage:link
Seed opcional sem make:
docker compose exec -T -u www-data laravel php getseeds
docker exec -i odb_mysql mysql -uroot -psecret odbdocker < storage/Location*.sql
docker exec -i odb_mysql mysql -uroot -psecret odbdocker < storage/Taxon*.sql
rm storage/Location*.sql storage/Taxon*.sql
Persistência de dados
Os contêineres criados pelo Docker podem ser excluídos e recriados sem perder os dados As tabelas MySQL são armazenadas em um volume; se ele for apagado, a base de dados será excluída.
docker volume list
Usando
O arquivo Makefile contém os seguintes comandos para interagir com os contêineres do docker e o odb.
Comandos para construir e criar o app
make docker-init- copia.env.docker(se faltar), constroi/sobe containers, instala composer, gera key, migra e faz storage:linkmake build- construir os contêineresmake key-generate- gerar a chave do app e adicioná-la ao .envmake composer-install- instalar dependências phpmake composer-update- atualizar dependências phpmake composer-dump-autoload- executar o dump-autoload do composer dentro do contêinermake migrate- criar ou atualizar o banco de dadosmake drop-migrate- apaga a base de dados e migra novamentemake seed-odb- popular o banco de dados com localizações e táxons
Comandos para acessar os contêineres docker
make start- iniciar todos os contêineresmake stop- parar todos os contêineresmake restart- reiniciar todos os contêineresmake ssh- entrar no contêiner principal da aplicação laravelmake ssh-mysql- entrar no contêiner mysql, para que você possa acessar o log do banco de dados usandomysql -uUSER -pPWDmake mysql- entrar no console docker do mysqlmake ssh-nginx- entrar no contêiner nginxmake ssh-supervisord- entrar no contêiner supervisord
Comandos de manutenção
make optimize- limpar caches e arquivos de logmake info- mostrar informações do appmake logs- mostrar logs do laravelmake logs-mysql- mostrar logs do mysqlmake logs-nginx- mostrar logs do nginxmake logs-supervisord- mostrar logs do supervisord
Recriando os containers
Se você tiver problemas e alterou os arquivos do docker, pode ser necessário reconstruir:
#apaga todas as imagens sem apagr a base de dados
make stop #pare todas
docker system prune -a #aceitar com Yes
#se quiser pagar os dados
docker volume list
docker volume rm VOLUME_ID
#construa novamente
make build
make start
Atualizando uma instalação Docker existente
Antes de atualizar, faça backup do banco de dados e de storage/app/public/media.
Antes de rodar os comandos, revise diferencas de configuracao da versao alvo:
- Compare
.envcom.env.example(incluindoassets_url) - Confira configuracoes PHP do perfil alvo (
docker/prod/php.iniou seu arquivo customizado) - Confira configuracao do Supervisor (
docker/supervisord.confou equivalente no seu deploy)
- Atualize o código-fonte para a versão desejada:
cd opendatabio
git fetch --tags
git checkout <tag-ou-branch-de-destino>
- Reconstrua e reinicie os contêineres:
make stop
make build
make start
- Atualize dependências PHP e rode as migrações:
make composer-install
make migrate
- Recompile os assets frontend apos mudancas no
.env:
npm run build
- Atualize os caches do Laravel e reinicie os workers de fila:
make optimize
docker compose exec -T -u www-data laravel php artisan queue:restart
Se a nova versão incluir mudanças no .env, adicione as novas chaves antes de rodar assets/cache/restart em produção.
2.4 - Instalação com Nginx
Estas instruções são para instalação com nginx. Se preferir Apache, use a página de instalação padrão (Apache).
Requisitos do servidor
- Versão suportada do PHP >= 8.2 (8.3 recomendado).
- Servidor web: nginx.
- Banco SQL: MySQL ou MariaDB (testado com MySQL 8.0 e MariaDB 10.6+).
- Extensões PHP necessárias:
openssl,pdo,pdo_mysql,mbstring,tokenizer,xml,dom,gd,exif,bcmath,zip,curl,redis. - Redis para filas/cache.
- Tectonic para geração de PDF de etiquetas.
- Pandoc para renderização bibliográfica (recomendado).
- Supervisor para jobs em segundo plano.
Configuração do site no nginx
Crie o arquivo do site (exemplo):
sudo nano /etc/nginx/sites-available/opendatabio
Use este bloco base (ajuste domínio/caminhos):
server {
listen 80;
server_name seu-dominio.exemplo;
root /home/odbserver/opendatabio/public;
index index.php index.html;
charset utf-8;
client_max_body_size 300M;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php8.3-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
fastcgi_read_timeout 300;
}
location ~ /\. {
deny all;
}
}
Ative e recarregue:
sudo ln -s /etc/nginx/sites-available/opendatabio /etc/nginx/sites-enabled/opendatabio
sudo nginx -t
sudo systemctl reload nginx
Content Security Policy (CSP)
No mesmo arquivo do site nginx, adicione no bloco server { ... }:
add_header Content-Security-Policy-Report-Only "
default-src 'self';
base-uri 'self';
form-action 'self';
frame-ancestors 'self';
object-src 'none';
script-src 'self' 'unsafe-eval';
style-src 'self' 'unsafe-inline';
img-src 'self' data: https://server.arcgisonline.com https://*.tile.openstreetmap.org;
font-src 'self' data:;
connect-src 'self';
" always;
Depois recarregue:
sudo nginx -t
sudo systemctl reload nginx
Notas:
- Comece com
Report-Onlye depois migre para enforcement após validar logs. https://server.arcgisonline.comehttps://*.tile.openstreetmap.orgsão necessários para os tiles do mapa.
Instalações em subcaminho (/opendatabio)
Se sua instalação roda em subcaminho (por exemplo http://localhost/opendatabio), ajuste no .env:
APP_URL=http://localhost/opendatabio
ASSET_URL=http://localhost/opendatabio
Depois atualize os assets gerados e arquivos do Livewire:
php artisan livewire:publish --assets
php artisan optimize:clear
npm run build
Etapas compartilhadas da aplicação
Para evitar redundância, use as mesmas seções da instalação Apache (também válidas para implantação com nginx):
- Configurações de PHP (php.ini) em Instalação padrão
- Configurar o supervisord em Instalação padrão
- Permissões de arquivos e pastas em Instalação padrão
- Instale OpenDataBio em Instalação padrão
- Configurações pós-instalação em Instalação padrão
2.5 - Personalizar a instalação
Mudanças simples que podem ser implementadas no layout de um site OpenDataBio
Logo e imagem de fundo
Para substituir o logotipo da barra de navegação e a imagem da página inicial,
apenas coloque seus arquivos de imagem substituindo os arquivos em /public/custom/ sem alterar seus nomes.
Textos e informações
Para alterar o texto de boas-vindas da página inicial, altere os valores para cada entrada nos arquivos:
/resources/lang/en/customs.php/resources/lang/pt-br/customs.php- Não remova as chaves de entrada. Defina como
nullpara suprimir a exibição no rodapé e na página inicial.
Documentação Local
Você pode adicionar documentação em formato *.md para o repositório em arquivos nas seguintes pastas:
/resources/docs/en/*/resources/docs/pt/*
Este espaço é reservado para administradores definirem documentação e diretivas personalizadas para os usuários de uma instalação específica do OpenDataBio. Por exemplo, este é um espaço para adicionar um código de conduta para os usuários, quem contatar para se tornar um usuário pleno,tutoriais específicos, etc.
NavBar e Rodapé
- Se você deseja alterar a cor da barra de navegação superior e do rodapé,
basta substituir a classe css Boostrap 5 nas tags e arquivos correspondentes na pasta
/resources/view/layout. - Você pode adicionar html adicional ao rodapé e barra de navegação, alterar o tamanho do logotipo, etc… como desejar.
2.6 - Atualizar OpenDataBio
Use este guia para atualizar uma instalacao existente do OpenDataBio com o minimo de indisponibilidade.
Antes de comecar
- Leia as notas da versao de destino e confirme se ha mudancas que exigem atencao.
- Faca backup de pelo menos:
- Dump do banco de dados
.envstorage/app/public/media
- Compare as configuracoes atuais com os modelos/configs da versao alvo:
.envcom.env.example(incluindoASSET_URL)- Configuracao do Supervisor (
/etc/supervisor/conf.d/opendatabio-worker.confou equivalente no container) - Configuracao do PHP (
php.inide CLI e FPM/Apache)
- Planeje uma janela de manutencao para ambiente de producao.
Atualizacao (instalacao Apache ou nginx)
- Coloque a aplicacao em modo manutencao:
cd /home/odbserver/opendatabio
php artisan down
- Atualize o codigo-fonte:
git fetch --tags
git checkout <target-tag-or-branch>
- Instale dependencias e rode as migracoes:
composer install --no-dev --optimize-autoloader
php artisan migrate:status
php artisan migrate --force
- Recompile os assets frontend apos mudancas no
.env(obrigatorio quandoASSET_URLmuda):
npm ci #talvez precise disso antes
npm run build
- Limpe cache e log e reinicie os workers:
php artisan optimize:clear
php artisan config:cache
php artisan queue:restart
systemctl restart supervisor.service, nginx+phpfpm or apache, mysql or mariadb
echo "" > storage/logs/laravel.log
echo "" > storage/logs/supervisor.log
- Coloque a aplicacao online novamente:
php artisan up
Atualizacao (instalacao Docker)
- Atualize o codigo-fonte:
cd opendatabio
git fetch --tags
git checkout <target-tag-or-branch>
- Reconstrua e reinicie os containers:
make stop
make build
make start
- Instale dependencias e rode as migracoes:
make composer-install
make migrate
- Recompile os assets frontend apos mudancas no
.env(obrigatorio quandoassets_urlmuda):
npm run build
- Limpe cache e reinicie os workers:
make optimize
docker compose exec -T -u www-data laravel php artisan queue:restart
Variaveis de ambiente
Se a nova versao adicionar variaveis de ambiente, compare .env com .env.example e adicione as chaves faltantes antes de asset/cache/restart em producao.
Estrategia de rollback
Se algo falhar depois das migracoes:
- Mantenha o modo manutencao ativo.
- Restaure backup do banco e do
.env. - Retorne para a tag anterior estavel.
- Reinstale dependencias/reconstrua containers e valide logs antes de
php artisan up.
3 - Serviços de API
Cada instalação do OpenDataBio fornece um serviço de API, permitindo aos usuários OBTER, INSERIR, ATUALIZAR dados programaticamente. O serviço é de acesso aberto a dados públicos, e requer autenticação do usuário para INSERIR e ATUALIZAR dados, ou para OBTER dados de acesso restrito.
O pacote OpenDataBio é um cliente para esta API, permitindo a interação com o repositório de dados diretamente do R.
A API OpenDataBio permite a consulta ao banco de dados e a importação/edição de dados por meio de uma interface inspirada em REST.
Todas as solicitações e respostas da API são formatadas em JSON.
A interação com a API do OpenDataBio
Uma simples chamada para a API OpenDataBio possui quatro partes independentes:
[verbo HTTP] + URL base + endpoint + parâmetros de solicitação
- HTTP-verbo -
GETpara exportações,POSTpara importações ePUTpara atualizações. - URL-base - o URL usado para acessar seu servidor OpenDataBio + mais
/ api / v0. Por exemplo,http:// opendatabio.inpa.gov.br/api/v0 - endpoint - representa o objeto ou coleção de objetos que você deseja acessar, por exemplo, para consultar nomes taxonômicos, o endpoint é “taxons”
- parâmetros de solicitação - representam a filtragem e o processamento que devem ser feitos com os objetos e são representados na chamada da API após um ponto de interrogação. Por exemplo, para recuperar apenas nomes taxonômicos válidos finalize a solicitação com
?valid = 1.
A chamada API acima pode ser inserida em um navegador para OBTER dados de acesso público. Por exemplo, para obter a lista de táxons válidos de uma instalação do OpenDataBio, a solicitação da API poderia ser:
https://opendb.inpa.gov.br/api/v0/taxons?valid=1&limit=10
Quando usar o OpenDataBio R package essa mesma chamada seria algo como odb_get_taxons(list(valid=1,limit=10)).
A resposta será algo como:
{
"meta":
{
"odb_version":"0.9.1-alpha1",
"api_version":"v0",
"server":"http://opendb.inpa.gov.br",
"full_url":"https://opendb.inpa.gov.br/api/v0/taxons?valid=1&limit1&offset=100"},
"data":
[
{
"id":62,
"parent_id":25,
"author_id":null,
"scientificName":"Laurales",
"taxonRank":"Ordem",
"scientificNameAuthorship":null,
"namePublishedIn":"Juss. ex Bercht. & J. Presl. In: Prir. Rostlin: 235. (1820).",
"parentName":"Magnoliidae",
"family":null,
"taxonRemarks":null,
"taxonomicStatus":"accepted",
"ScientificNameID":"http:\/\/tropicos.org\/Name\/43000015 | https:\/\/www.gbif.org\/species\/407",
"basisOfRecord":"Taxon"
}]}
Autenticação da API
- Não é obrigatória para obter quaisquer dados de acesso público numa base de dados ODB, que por padrão inclui Localidades, Taxons, Referências Bibliográficas, Pessoas e Variáveis.
- Autenticação é necessária para OBTER quaisquer dados que não sejam de acesso público e para INSERIR e ATUALIZAR dados.
- A autenticação é feita usando um
token API, que pode ser encontrado no seu perfil de usuário na interface do aplicativo. O token é atribuído a um único usuário do banco de dados e não deve ser compartilhado, exposto, enviado por e-mail ou armazenado em controles de versão. - Para autenticar na API OpenDataBio, use o token no cabeçalho “Authorization” da solicitação da API.
Os usuários terão acesso somente aos dados para os quais o usuário tem permissão e para quaisquer dados com acesso público na base de dados. O acesso à Medições, Indivíduos, Vouchers e Mídia depende das permissões compreendidas pelo token do usuário.
Versões da API
A API OpenDataBio segue seu próprio número de versão. Isso significa que o cliente pode esperar usar o mesmo código e obter as mesmas respostas, independentemente da versão do OpenDataBio que o servidor está executando. Todas as alterações feitas na mesma versão da API devem ser compatíveis com versões anteriores. Nosso controle de versão da API é controlado pelo URL, portanto, para solicitar uma versão específica da API, use o número da versão entre o URL base e o endpoint:
https://opendb.inpa.gov.br/api/v1/taxons
https://opendb.inpa.gov.br/api/v2/taxons
3.1 - Referência rápida
base-URL + ‘/api/v0/’ + endpoint + ‘?’ + request-parameters
https://opendb.inpa.gov.br/api/v0/taxons?valid=1&level=210&limit=2&offset=10
OBTER DADOS - GET
Parâmetros GET compartilhados
Os parâmetros limit e offset podem ser usados para dividir sua busca em partes.
Alternativamente, use a opção save_job=T e depois baixe os dados com o parametro get_file=T da API userjobs.
Alguns parâmetros aceitam um asterisco como curinga, então api/v0/taxons?name=Euterpe retornará táxons com nome exatamente como “Euterpe”, enquanto api/v0/taxons?name=Eut* retornará nomes começando com “Eut”.
Quando múltiplos parâmetros são especificados eles são combinados com o operador AND. Não há opção de parâmetro OR nas suas buscas.
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
Parâmetros GET específicos
| Endpoint | Descrição | Parâmetros |
|---|---|---|
| / | Testa seu acesso/token. | — |
| bibreferences | Referências bibliográficas (GET lista, POST cria). | id, bibkey, biocollection, dataset, fields, job_id, limit, offset, save_job, search, taxon, taxon_root |
| biocollections | Biocoleções (GET lista, POST cria). | id, acronym, fields, irn, job_id, limit, name, offset, save_job, search |
| datasets | Datasets e arquivos de versões publicadas (GET lista, POST cria via job de importação). | id, bibreference, fields, file_name, has_versions, include_url, limit, list_versions, name, offset, project, save_job, search, summarize, tag, tagged_with, taxon, taxon_root, traits |
| individuals | Indivíduos (GET lista, POST cria, PUT atualiza). | id, dataset, date_max, date_min, fields, job_id, limit, location, location_root, odbrequest_id, offset, person, project, save_job, tag, taxon, taxon_root, trait, vernacular |
| individual-locations | Ocorrências para indivíduos com múltiplas localizações (GET lista, POST/PUT grava). | id, dataset, date_max, date_min, fields, individual, limit, location, location_root, offset, person, project, save_job, tag, taxon, taxon_root |
| languages | Lista idiomas disponíveis. | fields, limit, offset |
| locations | Localidades (GET lista, POST cria, PUT atualiza). | id, adm_level, dataset, fields, job_id, lat, limit, location_root, long, name, offset, parent_id, project, querytype, root, save_job, search, taxon, taxon_root, trait |
| measurements | Medições de traits (GET lista, POST cria via job de importação, PUT atualiza). | id, bibreference, dataset, date_max, date_min, fields, individual, job_id, limit, location, location_root, measured_id, measured_type, offset, person, project, save_job, taxon, taxon_root, trait, trait_type, voucher |
| media | Metadados de mídia (GET lista, POST cria, PUT atualiza). | id, dataset, fields, individual, job_id, limit, location, location_root, media_id, media_uuid, offset, person, project, save_job, tag, taxon, taxon_root, uuid, voucher |
| persons | Pessoas (GET lista, POST cria, PUT atualiza). | id, abbrev, email, fields, job_id, limit, name, offset, save_job, search |
| projects | Projetos (GET lista). | id, fields, job_id, limit, offset, save_job, search, tag |
| taxons | Nomes taxonômicos (GET lista, POST cria). | id, bibreference, biocollection, dataset, external, fields, job_id, level, limit, location_root, name, offset, person, project, root, save_job, taxon_root, trait, valid, vernacular |
| traits | Definições de traits (GET lista, POST cria). | id, bibreference, categories, dataset, fields, job_id, language, limit, name, object_type, offset, save_job, search, tag, taxon, taxon_root, trait, type |
| vernaculars | Nomes vernáculos (GET lista, POST cria). | id, fields, individual, job_id, limit, location, location_root, offset, save_job, taxon, taxon_root |
| vouchers | Vouchers de coleção (GET lista, POST cria, PUT atualiza). | id, bibreference, bibreference_id, biocollection, biocollection_id, collector, dataset, date_max, date_min, fields, individual, job_id, limit, location, location_root, main_collector, number, odbrequest_id, offset, person, project, save_job, taxon, taxon_root, trait, vernacular |
| userjobs | Jobs em background (importações/exportações) (GET lista). | id, fields, get_file, limit, offset, status |
| activities | Lista entradas do log de atividades. | id, description, fields, individual, language, limit, location, log_name, measurement, offset, save_job, subject, subject_id, taxon, taxon_root, voucher |
| tags | Tags/palavras-chave (GET lista). | id, dataset, fields, job_id, language, limit, name, offset, project, save_job, search, trait |
Importar ou Validar dados - POST
A importação de dados requer a especificação dos parâmetros do verbo POST da API listados abaixo e isso vale também para a importação através de arquivos via interface web.
Através da POST API é também possível enviar um conjunto de coordenadas geográficas (latitude e longitude) para validação e obter as localidades espacialmente relacionas (parcelas, unidades administrativas, etc..), sem registrar nada na base de dados. Usuários registrados tem acesso ao serviço.
| Endpoint | Descrição | Parâmetros |
|---|---|---|
| bibreferences | Referências bibliográficas (GET lista, POST cria). | bibtex, doi |
| biocollections | Biocoleções (GET lista, POST cria). | acronym, name |
| individuals | Indivíduos (GET lista, POST cria, PUT atualiza). | altitude, angle, biocollection, biocollection_number, biocollection_type, collector, dataset, date, distance, identification_based_on_biocollection, identification_based_on_biocollection_number, identification_date, identification_individual, identification_notes, identifier, latitude, location, location_date_time, location_notes, longitude, modifier, notes, tag, taxon, x, y |
| individual-locations | Ocorrências para indivíduos com múltiplas localizações (GET lista, POST/PUT grava). | altitude, angle, distance, individual, latitude, location, location_date_time, location_notes, longitude, x, y |
| locations | Localidades (GET lista, POST cria, PUT atualiza). | adm_level, altitude, azimuth, datum, geojson, geom, ismarine, lat, long, name, notes, parent, startx, starty, x, y |
| locations-validation | Valida coordenadas com locais registrados (POST). | latitude, longitude |
| measurements | Medições de traits (GET lista, POST cria via job de importação, PUT atualiza). | bibreference, dataset, date, duplicated, link_id, location, notes, object_id, object_type, parent_measurement, person, trait_id, value |
| media | Metadados de mídia (GET lista, POST cria, PUT atualiza). | collector, dataset, date, filename, latitude, license, location, longitude, notes, object_id, object_type, project, tags, title_en, title_pt |
| persons | Pessoas (GET lista, POST cria, PUT atualiza). | abbreviation, biocollection, email, full_name, institution |
| taxons | Nomes taxonômicos (GET lista, POST cria). | author, author_id, bibreference, gbif, ipni, level, mobot, mycobank, name, parent, person, valid, zoobank |
| traits | Definições de traits (GET lista, POST cria). | bibreference, categories, description, export_name, link_type, name, objects, parent, range_max, range_min, tags, type, unit, value_length, wavenumber_max, wavenumber_min |
| vernaculars | Nomes vernáculos (GET lista, POST cria). | citations, individuals, language, name, notes, parent, taxons, type |
| vouchers | Vouchers de coleção (GET lista, POST cria, PUT atualiza). | biocollection, biocollection_number, biocollection_type, collector, dataset, date, individual, notes, number |
| datasets | Datasets e arquivos de versões publicadas (GET lista, POST cria via job de importação). | description, license, name, privacy, project_id, title |
Atualizar dados - PUT
Somente os endpoints listados abaixo podem ser atualizados usando a API e somente os campos PUT listados podem ser atualizados em cada endpoint.
Os valores dos campos são os mesmos como explicados para a API POST, exceto que em todos os casos o id do registro a ser atualizado também deve ser fornecido.
| Endpoint | Descrição | Parâmetros |
|---|---|---|
| individuals | Indivíduos (GET lista, POST cria, PUT atualiza). | id, collector, dataset, date, identification_based_on_biocollection, identification_based_on_biocollection_number, identification_date, identification_individual, identification_notes, identifier, individual_id, modifier, notes, tag, taxon |
| individual-locations | Ocorrências para indivíduos com múltiplas localizações (GET lista, POST/PUT grava). | id, altitude, angle, distance, individual, individual_location_id, latitude, location, location_date_time, location_notes, longitude, x, y |
| locations | Localidades (GET lista, POST cria, PUT atualiza). | id, adm_level, altitude, datum, geom, ismarine, lat, location_id, long, name, notes, parent, startx, starty, x, y |
| measurements | Medições de traits (GET lista, POST cria via job de importação, PUT atualiza). | id, bibreference, dataset, date, duplicated, link_id, location, measurement_id, notes, object_id, object_type, parent_measurement, person, trait_id, value |
| media | Metadados de mídia (GET lista, POST cria, PUT atualiza). | id, collector, dataset, date, latitude, license, location, longitude, media_id, media_uuid, notes, project, tags, title_en, title_pt |
| persons | Pessoas (GET lista, POST cria, PUT atualiza). | id, abbreviation, biocollection, email, full_name, institution, person_id |
| vouchers | Vouchers de coleção (GET lista, POST cria, PUT atualiza). | id, biocollection, biocollection_number, biocollection_type, collector, dataset, date, individual, notes, number, voucher_id |
Nomenclature Types
| Tipo Nomenclatural : código numérico | |
|---|---|
| NotType : 0 | Isosyntype : 8 |
| Type : 1 | Neotype : 9 |
| Holotype : 2 | Epitype : 10 |
| Isotype : 3 | Isoepitype : 11 |
| Paratype : 4 | Cultivartype : 12 |
| Lectotype : 5 | Clonotype : 13 |
| Isolectotype : 6 | Topotype : 14 |
| Syntype : 7 | Phototype : 15 |
Níveis taxonômicos (Ranks)
| Código | Nível |
|---|---|
| -100 | clade |
| 0 | kingdom |
| 10 | subkingd. |
| 30 | div., phyl., phylum, division |
| 40 | subdiv. |
| 60 | cl., class |
| 70 | subcl., subclass |
| 80 | superord., superorder |
| 90 | ord., order |
| 100 | subord. |
| 120 | fam., family |
| 130 | subfam., subfamily |
| 150 | tr., tribe |
| 180 | gen., genus |
| 190 | subg., subgenus, sect. |
| 210 | section, sp., spec., species |
| 220 | subsp., subspecies |
| 240 | var., variety |
| 270 | f., fo., form |
3.2 - Obter dados - GET
- O pacote OpenDataBio é um cliente para esta API, exemplos de uso aqui;
- Token de autenticação necessário apenas para obter dados com uma política de acesso não pública
Parâmetros GET compartilhados
Os parâmetros limit e offset podem ser usados para dividir sua busca em partes.
Alternativamente, use a opção save_job=T e depois baixe os dados com o parametro get_file=T da API userjobs.
Alguns parâmetros aceitam um asterisco como curinga, então api/v0/taxons?name=Euterpe retornará táxons com nome exatamente como “Euterpe”, enquanto api/v0/taxons?name=Eut* retornará nomes começando com “Eut”.
Quando múltiplos parâmetros são especificados eles são combinados com o operador AND. Não há opção de parâmetro OR nas suas buscas.
Endpoints GET
Links rápidos
- /
- bibreferences
- biocollections
- datasets
- individuals
- individual-locations
- languages
- locations
- measurements
- media
- persons
- projects
- taxons
- traits
- vernaculars
- vouchers
- userjobs
- activities
- tags
/ (GET)
Testa seu acesso/token.
Nenhum parâmetro para este endpoint.
bibreferences (GET)
Referências bibliográficas (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
bibkey | Não | Bibkey ou lista de bibkeys. | ducke1953,mayr1992 |
biocollection | Não | Id/nome/sigla de biocoleção; retorna referências que citam vouchers dessas coleções. | INPA |
dataset | Não | Id ou nome de dataset; retorna referências ligadas ao dataset. | Forest1 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Busca full-text no bibtex em modo booleano; espaços funcionam como AND. | Amazon forest |
taxon | Não | Lista de ids ou nomes canônicos de taxon; retorna referências ligadas ao taxon. | Ocotea guianensis,Minquartia guianensis ou 120,455 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
Campos retornados
Campos (simple): id, bibkey, year, author, title, doi, url, bibtex
Campos (all): id, bibkey, year, author, title, doi, url, bibtex
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 2,
"bibkey": "Riberiroetal1999FloraDucke",
"year": 1999,
"author": "José Eduardo Lahoz Da Silva Ribeiro and Michael John Gilbert Hopkins and Alberto Vicentini and Cynthia Anne Sothers and Maria Auxiliadora Da Silva Costa and Joneide Mouzinho De Brito and Maria Anália Duarte De Souza and Lúcia Helena Pinheiro Martins and Lúcia Garcez Lohmann and Paulo Apóstolo Costa Lima Assunção and Everaldo Da Costa Pereira and Cosme Fernandes Da Silva and Mariana Rabello Mesquita and Lilian Costa Procópio",
"title": "Flora Da Reserva Ducke: Guia De Identificação Das Plantas Vasculares De Uma Floresta De Terra Firme Na Amazônica Central",
"doi": null,
"url": null,
"bibtex": "@Article{Riberiroetal1999FloraDucke,\r\n title = {Flora da Reserva Ducke: Guia de Identifica{\\c{c}}{\\~a}o das Plantas Vasculares de uma Floresta de Terra Firme na Amaz{\\^o}nica Central},\r\n author = {José Eduardo Lahoz da Silva Ribeiro and Michael John Gilbert Hopkins and Alberto Vicentini and Cynthia Anne Sothers and Maria Auxiliadora da Silva Costa and Joneide Mouzinho de Brito and Maria Anália Duarte de Souza and Lúcia Helena Pinheiro Martins and Lúcia Garcez Lohmann and Paulo Apóstolo Costa Lima Assunç{ã}o and Everaldo da Costa Pereira and Cosme Fernandes da Silva and Mariana Rabello Mesquita and Lilian Costa Procópio},\r\n journal = {Flora da Reserva Ducke: Guia de Identifica{\\c{c}}{\\~a}o das Plantas Vasculares de uma Floresta de Terra Firme na Amaz{\\^o}nica Central},\r\n year = {1999},\r\n publisher = {INPA-DFID Manaus},\r\n pages = {819p},\r\n}"
},
{
"id": 3,
"bibkey": "Sutter2006female",
"year": 2006,
"author": "D. Merino Sutter and P. I. Forster and P. K. Endress",
"title": "Female Flowers And Systematic Position Of Picrodendraceae (Euphorbiaceae S.l., Malpighiales)",
"doi": "10.1007/s00606-006-0414-0",
"url": "http://dx.doi.org/10.1007/s00606-006-0414-0",
"bibtex": "@article{Sutter2006female,\n author = {D. Merino Sutter and P. I. Forster and P. K. Endress},\n year = {2006},\n title = {Female flowers and systematic position of Picrodendraceae (Euphorbiaceae s.l., Malpighiales)},\n issn = {0378-2697 | 1615-6110},\n issue = {1-4},\n url = {http://dx.doi.org/10.1007/s00606-006-0414-0},\n doi = {10.1007/s00606-006-0414-0},\n volume = {261},\n page = {187-215},\n journal = {Plant Systematics and Evolution},\n journal_short = {Plant Syst. Evol.},\n published = {Springer Science and Business Media LLC}\n}"
}
]
}biocollections (GET)
Biocoleções (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
acronym | Não | Sigla da biocoleção. | INPA |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
irn | Não | IRN do Index Herbariorum para filtrar biocoleções. | 123456 |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
name | Não | Nome exato da biocoleção (string simples). | Herbário do INPA |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Parametro de busca de texto. | Silva |
Campos retornados
Campos (simple): id, acronym, name, irn
Campos (all): id, acronym, name, irn, country, city, address
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 1,
"acronym": "INPA",
"name": "Instituto Nacional de Pesquisas da Amazônia",
"irn": 124921,
"country": null,
"city": null,
"address": null
},
{
"id": 2,
"acronym": "SPB",
"name": "Universidade de São Paulo",
"irn": 126324,
"country": null,
"city": null,
"address": null
}
]
}datasets (GET)
Datasets e arquivos de versões publicadas (GET lista, POST cria via job de importação).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
bibreference | Não | Id ou bibkey da referência. | 34 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
file_name | Não | Nome do arquivo de versão de dataset para download. | 2_Organisms.csv |
has_versions | Não | Quando 1, retorna apenas datasets que possuem versões publicas. | 1 |
include_url | Não | Quando 1 com list_versions, inclui URL para download do arquivo. | 1 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
list_versions | Não | Se 1, lista arquivos de versões de dataset para os ids informados. | 1 |
name | Não | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Parametro de busca de texto. | Silva |
summarize | Não | Id do dataset para retornar sumarios de conteudo/taxonomia/traits. | 3 |
tag | Não | Tag/número/código do indivíduo. | A-1234 |
tagged_with | Não | Ids de tags (virgula) ou texto para filtrar datasets por tags (lista de ids ou full-text). | 12,13 ou copa folha |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
traits | Não | Lista de ids de traits (separados por virgula) para filtrar datasets. | 12,15 |
Campos retornados
Campos (simple): id, name, title, projectName, description, notes, contactEmail, taggedWidth, uuid
Campos (all): id, name, title, projectName, notes, privacyLevel, policy, description, measurements_count, contactEmail, taggedWidth, uuid
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 4,
"name": "PDBFF-FITO 1ha core plots 1-10cm dbh - TREELETS",
"title": "Arvoretas (1cm>DAP",
"projectName": "Projeto Dinâmica Biológica de Fragmentos Florestais (PDBFF-Data)",
"notes": null,
"privacyLevel": "Restrito a usuários autorizados",
"policy": null,
"description": "Contém o único censo de árvores de pequeno porte 1-10cm de diâmetro nas parcelas de 1ha do PDBFF, em 11 das 69 de parcelas permanentes de 1ha do Programa de Monitoramento de Plantas do PDBFF.",
"measurements_count": null,
"contactEmail": "example",
"taggedWidth": "Parcelas florestais | PDBFF | Fitodemográfico",
"uuid": "e1d8ce8d-4847-11f0-8e9f-9cb654b86224"
}
]
}individuals (GET)
Indivíduos (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
dataset | Não | Id/nome de dataset; com trait filtra por dataset_id de medições existentes, senão o dataset_id do indivíduo. | 3 ou FOREST1 |
date_max | Não | Data final inclusiva (AAAA-MM-DD) comparada com a data do indivíduo. | 2024-12-31 |
date_min | Não | Data inicial inclusiva (AAAA-MM-DD) comparada com a data do indivíduo. | 2020-01-01 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Lista de ids/nomes de locais; retorna indivíduos ligados à esses locais. | Parcela 25ha ou 55,60 |
location_root | Não | Id/nome de local; inclui descendentes dos locais informados; retorna individuos dentro dos locais informados | Amazonas |
odbrequest_id | Não | Id de request para filtrar indivíduos vinculados a esse pedido ODB. | 12 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
person | Não | Ids/nomes/abreviação/emails de coletores | Silva, J.B. da, Assunção, P.C.L. ou Paulo Apóstolo Costa Lima Assunção ou 3,567,300 |
project | Não | Id/nome de projeto; filtra indivíduos cujo dataset pertence ao projeto. | PDBFF |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
tag | Não | Filtro por tag/número de indivíduo; aceita lista separada por virgula. | A-123,2001,24,54 |
taxon | Não | Lista de ids/nomes de taxon; filtra pela identificacao exata (sem descendentes). | Licaria cannela ou 456 |
taxon_root | Não | Lista de ids/nomes de taxon; inclui descendentes de cada taxon. | Lauraceae |
trait | Não | Ids/export_name de traits; retorna indivíduos que tem medições para esses traits | 12,15 ou treeDbh,treeDbhPom |
vernacular | Não | Ids/nomes de vernáculos (nomes populares) vinculados à indivíduos. | castanha,itaúba,jacareúba ou 24,56,74 |
Campos retornados
Campos (simple): id, basisOfRecord, organismID, recordedByMain, recordNumber, recordedDate, family, scientificName, identificationQualifier, identifiedBy, dateIdentified, locationName, locationParentName, decimalLatitude, decimalLongitude, x, y, gx, gy, angle, distance, datasetName
Campos (all): id, basisOfRecord, organismID, recordedByMain, recordNumber, recordedDate, recordedBy, scientificName, scientificNameAuthorship, taxonPublishedStatus, genus, family, identificationQualifier, identifiedBy, dateIdentified, identificationRemarks, identificationBiocollection, identificationBiocollectionReference, locationName, higherGeography, decimalLatitude, decimalLongitude, georeferenceRemarks, locationParentName, x, y, gx, gy, angle, distance, organismRemarks, datasetName, uuid
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 306246,
"basisOfRecord": "Organism",
"organismID": "2639_Spruce_1852",
"recordedByMain": "Spruce, R.",
"recordNumber": "2639",
"recordedDate": "1852-10",
"recordedBy": "Spruce, R.",
"scientificName": "Ecclinusa lanceolata",
"scientificNameAuthorship": "(Mart. & Eichler) Pierre",
"taxonPublishedStatus": "published",
"genus": "Ecclinusa",
"family": "Sapotaceae",
"identificationQualifier": "",
"identifiedBy": "Spruce, R.",
"dateIdentified": "1852-10-00",
"identificationRemarks": "",
"identificationBiocollection": null,
"identificationBiocollectionReference": null,
"locationName": "São Gabriel da Cachoeira",
"higherGeography": "São Gabriel da Cachoeira < Amazonas < Brasil",
"decimalLatitude": 1.1841927,
"decimalLongitude": -66.80167715,
"georeferenceRemarks": "decimal coordinates are the CENTROID of the footprintWKT geometry",
"locationParentName": "Amazonas",
"x": null,
"y": null,
"gx": null,
"gy": null,
"angle": null,
"distance": null,
"organismRemarks": "prope Panure ad Rio Vaupes Amazonas, Brazil",
"datasetName": "Exsicatas LABOTAM",
"uuid": "c01000f0-f437-11ef-b90b-9cb654b86224"
}
]
}individual-locations (GET)
Ocorrências para indivíduos com múltiplas localizações (GET lista, POST/PUT grava).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
dataset | Não | Id/nome de dataset; filtra pelo dataset do indivíduo vinculado. | FOREST1 |
date_max | Não | Data/hora maxima; compara date_time ou data do indivíduo quando vazio. | 2024-12-31 |
date_min | Não | Data/hora minima; compara date_time ou data do indivíduo quando vazio. | 2020-01-01 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
individual | Não | Lista de ids de indivíduos com ocorrências retornadas. | 12,44 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
location_root | Não | Id/nome do local incluindo descendentes. | Amazonas ou 10 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
person | Não | Ids/nomes/emails de coletores; filtra pelas coletas dos indivíduos. | Silva, J.B.|23 |
project | Não | Id/nome de projeto; filtra ocorrências de indivíduos em datasets do projeto. | PDBFF |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
tag | Não | Lista de tags/números de indivíduo; compara com individuals.number. | A-123,B-2 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
Campos retornados
Campos (simple): id, individual_id, basisOfRecord, occurrenceID, organismID, recordedDate, locationName, higherGeography, decimalLatitude, decimalLongitude, x, y, angle, distance, minimumElevation, occurrenceRemarks, scientificName, family, datasetName
Campos (all): id, individual_id, basisOfRecord, occurrenceID, organismID, scientificName, family, recordedDate, locationName, higherGeography, decimalLatitude, decimalLongitude, georeferenceRemarks, x, y, angle, distance, minimumElevation, occurrenceRemarks, organismRemarks, datasetName
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 306244,
"individual_id": 306246,
"basisOfRecord": "Occurrence",
"occurrenceID": "2639_Spruce_1852.1852-10",
"organismID": "2639_Spruce_1852",
"scientificName": "Ecclinusa lanceolata",
"family": "Sapotaceae",
"recordedDate": "1852-10",
"locationName": "São Gabriel da Cachoeira",
"higherGeography": "Brasil > Amazonas > São Gabriel da Cachoeira",
"decimalLatitude": 1.1841927,
"decimalLongitude": -66.80167715,
"georeferenceRemarks": "decimal coordinates are the CENTROID of the footprintWKT geometry",
"x": null,
"y": null,
"angle": null,
"distance": null,
"minimumElevation": null,
"occurrenceRemarks": null,
"organismRemarks": "prope Panure ad Rio Vaupes Amazonas, Brazil",
"datasetName": "Exsicatas LABOTAM"
}
]
}languages (GET)
Lista idiomas disponíveis.
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
limit | Não | Quantidade maxima de registros retornados. | 100 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 1,
"code": "en",
"name": "English",
"is_locale": 1,
"created_at": null,
"updated_at": null
}
]
}locations (GET)
Localidades (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
adm_level | Não | Um ou mais códigos adm_level (separados por virgula ou array). | 10,100 |
dataset | Não | Id/nome de dataset; expande para todas as locations usadas pelo dataset. | FOREST1 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
lat | Não | Latitude (graus decimais) usada com querytype. | -3.11 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location_root | Não | Alias de root para compatibilidade. | Amazonas |
long | Não | Longitude (graus decimais) usada com querytype. | -60.02 |
name | Não | Correspondencia exata de nome; aceita lista de nomes ou ids. | Manaus |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
parent_id | Não | Id do pai para consultas hierarquicas. | 210 |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
querytype | Não | Quando lat/long informados: busca geometrica exact|parent|closest. | parent |
root | Não | Id/nome de local; retorna ele e todos os descendentes/relacionados. | Amazonas |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Busca prefixada no nome (SQL LIKE name%). | Mana |
taxon | Não | Lista de ids/nomes de taxon; filtra locations por identificações vinculadas. | Euterpe edulis |
taxon_root | Não | Lista de ids/nomes de taxon; inclui descendentes ao filtrar identificações vinculadas. | Lauraceae |
trait | Não | Id/nome de trait; so funciona junto com dataset para filtrar por measurements. | DBH |
Campos retornados
Campos (simple): id, basisOfRecord, locationName, adm_level, country_adm_level, x, y, startx, starty, distance_to_search, parent_id, parentName, higherGeography, footprintWKT, locationRemarks, decimalLatitude, decimalLongitude, georeferenceRemarks, geodeticDatum
Campos (all): id, basisOfRecord, locationName, adm_level, country_adm_level, x, y, startx, starty, distance_to_search, parent_id, parentName, higherGeography, footprintWKT, locationRemarks, decimalLatitude, decimalLongitude, georeferenceRemarks, geodeticDatum
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 27297,
"basisOfRecord": "Location",
"locationName": "Parcela 1105",
"adm_level": 100,
"country_adm_level": "Parcela",
"x": "100.00",
"y": "100.00",
"startx": null,
"starty": null,
"distance_to_search": null,
"parent_id": 27277,
"parentName": "Fazenda Esteio",
"higherGeography": "Brasil > Amazonas > Rio Preto da Eva > Fazenda Esteio > Parcela 1105",
"footprintWKT": "POLYGON((-59.81371985 -2.42215752,-59.81360263 -2.42126619,-59.81270751 -2.42136656,-59.81282469 -2.42225788,-59.81371985 -2.42215752))",
"locationRemarks": "source: Polígono desenhado a partir das coordenadas de GPS dos vértices; georeferencedBy: Diogo Martins Rosa & Ana Andrade; fundedBy: Edital CNPq-Brasil/LBA 458027/2013-8; geometryBy: Alberto Vicentini; geometryDate: 2021-09-29; warning: Conflito com polígono da UC de 2021. Este polígono deveria ter a mesma geometria do polígono correspondente que faz parte da UC ARIE PDBFF, mas como ele foi gerado pelas coordenadas de campo, foi mantida essa geometria. A UC, portanto, não protege adequadamente essa parcela de monitoramento.",
"decimalLatitude": -2.42215752,
"decimalLongitude": -59.81371985,
"georeferenceRemarks": "decimal coordinates are the START POINT in footprintWKT geometry",
"geodeticDatum": null
}
]
}measurements (GET)
Medições de traits (GET lista, POST cria via job de importação, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
bibreference | Não | Id ou bibkey da referência. | 34 |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date_max | Não | Filtra registros ate esta data (AAAA-MM-DD). | 2024-12-31 |
date_min | Não | Filtra registros a partir desta data (AAAA-MM-DD). | 2020-01-01 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
location_root | Não | Id/nome do local incluindo descendentes. | Amazonas ou 10 |
measured_id | Não | Filtro de measurement: id do objeto medido (coerente com measured_type). | 4521 |
measured_type | Não | Filtro de measurement: classe do objeto medido (Individual, Location, Taxon, Voucher, Media). | Media |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
person | Não | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). | Silva, J.B.|Costa, M. |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
trait | Não | Id ou export_name do trait para filtro. | DBH |
trait_type | Não | Filtra measurements pelo código do tipo de trait. | 1 |
voucher | Não | Id do voucher para filtrar measurements. | 102 |
Campos retornados
Campos (simple): id, basisOfRecord, measured_type, measured_id, measurementType, measurementValue, measurementUnit, measurementDeterminedBy, measurementDeterminedDate, scientificName, datasetName, family, sourceCitation
Campos (all): id, basisOfRecord, measured_type, measured_id, measurementType, measurementValue, measurementUnit, measurementDeterminedDate, measurementDeterminedBy, measurementRemarks, resourceRelationship, resourceRelationshipID, relationshipOfResource, scientificName, family, datasetName, measurementMethod, sourceCitation, measurementLocationId, measurementParentId, decimalLatitude, decimalLongitude
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 1,
"basisOfRecord": "MeasurementsOrFact",
"measured_type": "App\\Models\\Individual",
"measured_id": 86947,
"measurementType": "treeDbh",
"measurementValue": 13,
"measurementUnit": "cm",
"measurementDeterminedDate": "1979-11-14",
"measurementDeterminedBy": "Menezes, J.F. | Bahia, R.P. | Lima, J. | Santos, R.M. | Ferreira, A.J.C. | Cardoso, Romeu M.",
"measurementRemarks": null,
"resourceRelationship": null,
"resourceRelationshipID": "1202-1371_Menezes_1979",
"relationshipOfResource": "measurement of",
"scientificName": "Paramachaerium ormosioides",
"family": "Fabaceae",
"datasetName": "Censos 01 - PDBFF-FITO ForestPlots - 1979-1980",
"measurementMethod": "Name: Diameter at breast height - DBH | Definition:Diameter at breast height,, i.e. ca. 1.3 meters from the base of the trunk",
"sourceCitation": null,
"measurementLocationId": 28280,
"measurementParentId": null,
"decimalLatitude": -2.40371599,
"decimalLongitude": -59.87090972
}
]
}media (GET)
Metadados de mídia (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
location_root | Não | Id/nome do local incluindo descendentes. | Amazonas ou 10 |
media_id | Não | Id numerico de mídia. | 88 |
media_uuid | Não | UUID da mídia. | a3f0a4ac-6b5b-11ed-b8c0-0242ac120002 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
person | Não | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). | Silva, J.B.|Costa, M. |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
tag | Não | Tag/número/código do indivíduo. | A-1234 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
uuid | Não | — | |
voucher | Não | Id do voucher para filtrar measurements. | 102 |
Campos retornados
Campos (simple): id, model_type, model_id, basisOfRecord, recordedBy, recordedDate, dwcType, resourceRelationship, resourceRelationshipID, relationshipOfResource, scientificName, family, datasetName, projectName, taggedWith, accessRights, license, file_name, file_url, citation, uuid
Campos (all): id, model_type, model_id, basisOfRecord, recordedBy, recordedDate, dwcType, resourceRelationship, resourceRelationshipID, relationshipOfResource, scientificName, family, datasetName, projectName, taggedWith, accessRights, bibliographicCitation, license, file_name, file_url, citation, uuid, bibtex, userName, created_at
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 20211,
"model_type": "App\\Models\\Individual",
"model_id": 111785,
"basisOfRecord": "MachineObservation",
"recordedBy": "Francisco Javier Farroñay Pacaya",
"recordedDate": "2025-03-09",
"dwcType": "StillImage",
"resourceRelationship": "Organism",
"resourceRelationshipID": "3402-1134_Pereira_1986",
"relationshipOfResource": "StillImage of ",
"scientificName": "Sacoglottis guianensis",
"family": "Humiriaceae",
"datasetName": "Unknown dataset",
"projectName": "Projeto Dinâmica Biológica de Fragmentos Florestais",
"taggedWith": "Folha abaxial",
"accessRights": "Open access.",
"bibliographicCitation": "Sacoglottis guianensis (Humiriaceae). (2025). By Francisco Javier Farroñay Pacaya. Collection: Pereira, M.J.R. #3402-1134 on 1986-01-24, from Quadrante 52, Parcela 3402-3, Reserva 3402, Cabo Frio, Fazenda Porto Alegre, Amazonas, Brasil (PDBFF). Project: PDBFF-Data. Instituto Nacional de Pesquisas da Amazônia (INPA), Manaus, Amazonas, Brasil. Type: Image. License: CC-BY-NC-SA 4.0. uuid: inpa-odb-3f139ba4-f22b-42d8-9e74-c340309061c2, url: http://localhost/opendatabio",
"license": "CC-BY-NC-SA 4.0",
"file_name": "67ce28cd76f4a.jpg",
"file_url": "http://localhost/opendatabio/storage/media/20211/67ce28cd76f4a.jpg",
"citation": "Sacoglottis guianensis (Humiriaceae). (2025). By Francisco Javier Farroñay Pacaya. Collection: Pereira, M.J.R. #3402-1134 on 1986-01-24, from Quadrante 52, Parcela 3402-3, Reserva 3402, Cabo Frio, Fazenda Porto Alegre, Amazonas, Brasil (PDBFF). Project: PDBFF-Data. Instituto Nacional de Pesquisas da Amazônia (INPA), Manaus, Amazonas, Brasil. Type: Image. License: CC-BY-NC-SA 4.0. uuid: inpa-odb-3f139ba4-f22b-42d8-9e74-c340309061c2, url: http://localhost/opendatabio",
"uuid": "3f139ba4-f22b-42d8-9e74-c340309061c2",
"bibtex": "@misc{Farronay_2025_20211,\n{\n \"title\": \" Sacoglottis guianensis (Humiriaceae)\",\n \"year\": \"(2025)\",\n \"author\": \"Francisco Javier Farroñay Pacaya\",\n \"howpublished\": \"{http:\\/\\/localhost\\/opendatabio\\/media\\/uuid\\/3f139ba4-f22b-42d8-9e74-c340309061c2}\",\n \"license\": \"CC-BY-NC-SA 4.0\",\n \"note\": \"Type: Image; Collection: Pereira, M.J.R. #3402-1134 on 1986-01-24, from Quadrante 52, Parcela 3402-3, Reserva 3402, Cabo Frio, Fazenda Porto Alegre, Amazonas, Brasil (PDBFF); Coordinates: POINT(-59.91500315727877 -2.3929141688648765); License: CC-BY-NC-SA 4.0; Project: PDBFF-Data.; Accessed: 2026-02-04\",\n \"publisher\": \"Instituto Nacional de Pesquisas da Amazônia (INPA), Manaus, Amazonas, Brasil\"\n}\n}",
"userName": "example",
"created_at": "2025-03-09T23:48:29.000000Z"
}
]
}persons (GET)
Pessoas (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
abbrev | Não | Busca por abreviação de pessoa. | Silva, J.B. |
email | Não | Endereco de email. | user@example.org |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
name | Não | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Parametro de busca de texto. | Silva |
Campos retornados
Campos (simple): id, full_name, abbreviation, emailAddress, institution, notes
Campos (all): id, full_name, abbreviation, emailAddress, institution, notes
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 3127,
"full_name": "Raimundo Afeganistão",
"abbreviation": "AFEGANISTÃO, R.",
"emailAddress": null,
"institution": null,
"notes": "PDBFF"
},
{
"id": 14,
"full_name": "Maria de Fátima Agra",
"abbreviation": "Agra, M.F.",
"emailAddress": null,
"institution": null,
"notes": null
},
{
"id": 15,
"full_name": "J. L. A. Aguiar Jr",
"abbreviation": "Aguiar Jr., J.L.A.",
"emailAddress": null,
"institution": null,
"notes": null
}
]
}projects (GET)
Projetos (GET lista).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Parametro de busca de texto. | Silva |
tag | Não | Tag/número/código do indivíduo. | A-1234 |
Campos retornados
Campos (simple): id, acronym, name, description
Campos (all): id, acronym, name, description, pages, urls, created_at, updated_at
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 1,
"acronym": "PDBFF-Data",
"name": "Projeto Dinâmica Biológica de Fragmentos Florestais",
"description": "Este espaço agrega conjuntos de dados de monitoramentos e pesquisas realizadas nas áreas amostrais do PDBFF, localizadas na Área de Relevante Interesse Ecológico - ARIE PDBFF.",
"pages": {
"en": null,
"pt-br": null
},
"urls": [
{
"url": "https://alfa-pdbff.site/",
"label": null,
"icon": "fa-solid fa-globe"
}
],
"created_at": "2022-10-31T07:01:18.000000Z",
"updated_at": "2023-11-17T21:08:55.000000Z"
}
]
}taxons (GET)
Nomes taxonômicos (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
bibreference | Não | Id ou bibkey da referência. | 34 |
biocollection | Não | Id, nome ou sigla da biocoleção. | INPA |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
external | Não | Flag para incluir ids externos (Tropicos, IPNI, etc.). | 1 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
level | Não | Código ou string do nível taxonômico. | 210 ou species |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location_root | Não | Id/nome do local incluindo descendentes. | Amazonas ou 10 |
name | Não | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
person | Não | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). | Silva, J.B.|Costa, M. |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
root | Não | Id raiz para consultas hierarquicas (taxon ou local). | 120 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
trait | Não | Id ou export_name do trait para filtro. | DBH |
valid | Não | Quando 1 retorna apenas nomes taxonômicos validos. | 1 |
vernacular | Não | Id ou nome de vernacular para filtrar individuals. | castanha|12 |
Campos retornados
Campos (simple): id, parent_id, author_id, scientificName, taxonRank, scientificNameAuthorship, namePublishedIn, parentName, family, taxonRemarks, taxonomicStatus, scientificNameID, basisOfRecord
Campos (all): id, senior_id, parent_id, author_id, scientificName, taxonRank, scientificNameAuthorship, namePublishedIn, parentName, family, higherClassification, taxonRemarks, taxonomicStatus, acceptedNameUsage, acceptedNameUsageID, parentNameUsage, scientificNameID, basisOfRecord
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 16332,
"senior_id": null,
"parent_id": 16331,
"author_id": null,
"scientificName": "Aiouea grandifolia",
"taxonRank": "Species",
"scientificNameAuthorship": "van der Werff",
"namePublishedIn": null,
"parentName": "Aiouea",
"family": "Lauraceae",
"higherClassification": "Eukaryota > Plantae > Viridiplantae > Embryophytes > Spermatopsida > Angiosperms > Magnoliidae > Laurales > Lauraceae > Aiouea",
"taxonRemarks": null,
"taxonomicStatus": "accepted",
"acceptedNameUsage": null,
"acceptedNameUsageID": null,
"parentNameUsage": "Aiouea",
"scientificNameID": "https://tropicos.org/Name/17806050 | https://www.gbif.org/species/4175896",
"basisOfRecord": "Taxon"
}
]
}traits (GET)
Definições de traits (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
bibreference | Não | Id ou bibkey da referência. | 34 |
categories | Não | Lista JSON de categorias de trait com lang/rank/name/description. | [{\"lang\":\"en\",\"rank\":1,\"name\":\"small\"}] |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
language | Não | Id/código/nome do idioma | en ou 1 ou english ou portugues ou pt-br |
limit | Não | Quantidade maxima de registros retornados. | 100 |
name | Não | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
object_type | Não | Tipo do objeto medido: Individual, Location, Taxon, Voucher ou Media. | Individual |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Parametro de busca de texto. | Silva |
tag | Não | Tag/número/código do indivíduo. | A-1234 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
trait | Não | Id ou export_name do trait para filtro. | DBH |
type | Não | Parametro generico type (código do trait ou tipo de vernacular: use/generic/etimology). | use ou 10 |
Campos retornados
Campos (simple): id, type, typename, export_name, unit, range_min, range_max, link_type, value_length, name, description, objects, measurementType, categories
Campos (all): id, type, typename, export_name, measurementType, measurementUnit, range_min, range_max, link_type, value_length, name, description, objects, measurementMethod, MeasurementTypeBibkeys, TaggedWith, categories
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 206,
"type": 1,
"typename": "QUANT_REAL",
"export_name": "treeDbh",
"measurementType": "treeDbh",
"measurementUnit": "cm",
"range_min": 0.1,
"range_max": 700,
"link_type": null,
"value_length": null,
"name": "Diâmetro à altura do peito – DAP",
"description": "Diâmetro à altura do peito, i.e. medido a ca. 1.3m desde a base do caule",
"objects": "App\\Models\\Individual | App\\Models\\Voucher | App\\Models\\Location | App\\Models\\Taxon | App\\Models\\Media",
"measurementMethod": "Name: Diameter at breast height - DBH | Definition:Diameter at breast height,, i.e. ca. 1.3 meters from the base of the trunk",
"MeasurementTypeBibkeys": "",
"TaggedWith": "",
"categories": null
},
{
"id": 207,
"type": 1,
"typename": "QUANT_REAL",
"export_name": "treeDbhPom",
"measurementType": "treeDbhPom",
"measurementUnit": "m",
"range_min": 0,
"range_max": 15,
"link_type": null,
"value_length": null,
"name": "Ponto de medição do DAP",
"description": "Ponto de medição do DAP, necessário quando impossível medir a 1.3 m",
"objects": "App\\Models\\Individual",
"measurementMethod": "Name: DBH Point of Measurement | Definition:DAP measuring height, necessary when impossible to measure at 1.3 m",
"MeasurementTypeBibkeys": "",
"TaggedWith": "",
"categories": null
},
{
"id": 524,
"type": 2,
"typename": "CATEGORICAL",
"export_name": "stemType",
"measurementType": "stemType",
"measurementUnit": null,
"range_min": null,
"range_max": null,
"link_type": null,
"value_length": null,
"name": "Tipo de fuste",
"description": "Tipo de fuste",
"objects": "App\\Models\\Voucher | App\\Models\\Individual | App\\Models\\Taxon",
"measurementMethod": "Name: Type of stem | Definition:Type of stem | Categories: CategoryName: Main stem | Definition:The main trunk, usually the thickest. | CategoryName: Secondary stem | Definition:A secondary trunk, there is a thicker one, which defines the area better. A shoot below 1.3 m high is a secondary trunk.",
"MeasurementTypeBibkeys": "",
"TaggedWith": "",
"categories": [
{
"id": 12990,
"name": "Fuste principal",
"description": "O tronco principal, geralmente o mais grosso.",
"rank": 1,
"belongs_to_trait": "stemType"
},
{
"id": 12991,
"name": "Fuste secundário",
"description": "Um tronco secundário, há outro mais grosso, que define melhor a área. Um rebroto abaixo de 1.3 m de altura é um tronco secundário.",
"rank": 2,
"belongs_to_trait": "stemType"
}
]
}
]
}vernaculars (GET)
Nomes vernáculos (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
location_root | Não | Id/nome do local incluindo descendentes. | Amazonas ou 10 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
Campos retornados
Campos (simple): id, name, languageName, notes, locationsList, taxonsList, individualsList, citationsArray
Campos (all): id, name, languageName, languageCode, notes, taxonsList, taxonsListArray, individualsList, individualsListArray, locationsList, locationsListArray, variantsList, variantsListArray, citationsArray, createdBy, created_at, updated_at
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 1,
"name": "itaúba-preta",
"languageName": "Portuguese",
"languageCode": "pt-br",
"notes": null,
"taxonsList": "Mezilaurus duckei",
"taxonsListArray": [
{
"id": 19774,
"scientificName": "Mezilaurus duckei",
"family": "Lauraceae"
}
],
"individualsList": "7739_Macedo_2023",
"individualsListArray": [
{
"id": 510747,
"uuid": "c75d9233-f437-11ef-b90b-9cb654b86224",
"organismId": "7739_Macedo_2023",
"scientificName": "Mezilaurus duckei",
"family": "Lauraceae"
}
],
"locationsList": null,
"locationsListArray": [],
"variantsList": "itaúba",
"variantsListArray": [
{
"id": 2,
"name": "itaúba",
"languageName": "Tupi",
"languageCode": "tup"
}
],
"citationsArray": [
{
"id": 2,
"citation": "ita = pedra; uba = árvore; preta em referência a cor da madeira",
"bibreference_id": null,
"bibreference_name": null,
"notes": null,
"type": "etimology",
"createdBy": "example"
}
],
"createdBy": "example",
"created_at": "2025-12-15T20:17:16.000000Z",
"updated_at": "2025-12-15T21:04:53.000000Z"
}
]
}vouchers (GET)
Vouchers de coleção (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
bibreference | Não | Id ou bibkey da referência. | 34 |
bibreference_id | Não | Lista de ids de BibReference para filtrar vouchers. | 10,11 |
biocollection | Não | Id, nome ou sigla da biocoleção. | INPA |
biocollection_id | Não | Lista de ids de biocoleção para filtrar vouchers. | 1,5 |
collector | Não | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date_max | Não | Filtra registros ate esta data (AAAA-MM-DD). | 2024-12-31 |
date_min | Não | Filtra registros a partir desta data (AAAA-MM-DD). | 2020-01-01 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
location_root | Não | Id/nome do local incluindo descendentes. | Amazonas ou 10 |
main_collector | Não | Booleano (1) para filtrar vouchers apenas pelo coletor principal. | 1 |
number | Não | Número/código de coletor (voucher ou tag quando diferente). | 1234A |
odbrequest_id | Não | Filtra indivíduos vinculados a um request id. | 12 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
person | Não | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). | Silva, J.B.|Costa, M. |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
trait | Não | Id ou export_name do trait para filtro. | DBH |
vernacular | Não | Id ou nome de vernacular para filtrar individuals. | castanha|12 |
Campos retornados
Campos (simple): id, individual_id, basisOfRecord, occurrenceID, organismID, collectionCode, catalogNumber, typeStatus, recordedByMain, recordNumber, recordedDate, recordedBy, scientificName, family, identificationQualifier, identifiedBy, dateIdentified, identificationRemarks, locationName, decimalLatitude, decimalLongitude, occurrenceRemarks, datasetName
Campos (all): id, individual_id, basisOfRecord, occurrenceID, organismID, collectionCode, catalogNumber, typeStatus, recordedByMain, recordNumber, recordedDate, recordedBy, scientificName, scientificNameAuthorship, taxonPublishedStatus, genus, family, identificationQualifier, identifiedBy, dateIdentified, identificationRemarks, locationName, higherGeography, decimalLatitude, decimalLongitude, georeferenceRemarks, occurrenceRemarks, datasetName, uuid
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 72209,
"individual_id": 306246,
"basisOfRecord": "PreservedSpecimens",
"occurrenceID": "2639.Spruce.K.K000640463",
"organismID": "2639_Spruce_1852",
"collectionCode": "K",
"catalogNumber": "K000640463",
"typeStatus": "Tipo",
"recordedByMain": "Spruce, R.",
"recordNumber": "2639",
"recordedDate": "1852-10",
"recordedBy": "Spruce, R.",
"scientificName": "Ecclinusa lanceolata",
"scientificNameAuthorship": "(Mart. & Eichler) Pierre",
"taxonPublishedStatus": "published",
"genus": "Ecclinusa",
"family": "Sapotaceae",
"identificationQualifier": "",
"identifiedBy": "Spruce, R.",
"dateIdentified": "1852-10-00",
"identificationRemarks": "",
"locationName": "São Gabriel da Cachoeira",
"higherGeography": "Brasil > Amazonas > São Gabriel da Cachoeira",
"decimalLatitude": 1.1841927,
"decimalLongitude": -66.80167715,
"georeferenceRemarks": "decimal coordinates are the CENTROID of the footprintWKT geometry",
"occurrenceRemarks": "OrganismRemarks = prope Panure ad Rio Vaupes Amazonas, Brazil",
"datasetName": "Exsicatas LABOTAM",
"uuid": "6302316f-2b48-43b5-816b-005df70d15c9"
}
]
}userjobs (GET)
Jobs em background (importações/exportações) (GET lista).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
get_file | Não | Quando 1 com userjobs id, retorna o arquivo salvo. | 1 |
limit | Não | Quantidade maxima de registros retornados. | 100 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
status | Não | Filtro de status de job (Submitted, Processing, Success, Failed, Cancelled). | Success |
Campos retornados
Campos (simple): id, dispatcher, status, percentage, created_at, affected_ids, affected_model
Campos (all): id, dispatcher, status, percentage, created_at, updated_at, affected_ids, affected_model, log
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 23652,
"dispatcher": "App\\Jobs\\BatchUpdateIndividuals",
"status": "Success",
"percentage": "100%",
"created_at": "2025-12-10T14:36:25.000000Z",
"updated_at": "2025-12-10T14:36:28.000000Z",
"affected_ids": [
86136,
57362,
85053,
72256,
74543
],
"affected_model": "App\\Models\\Individual",
"log": "[]"
}
]
}activities (GET)
Lista entradas do log de atividades.
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
description | Não | Descrição em texto ou mapa de traducao. | {\"en\":\"Leaf length\",\"pt-br\":\"Comprimento da folha\"} |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
language | Não | Id/código/nome do idioma | en ou 1 ou english ou portugues ou pt-br |
limit | Não | Quantidade maxima de registros retornados. | 100 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
log_name | Não | Filtro de activity log name. | default |
measurement | Não | Filtro de atividade: id de measurement. | 55 |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
subject | Não | Filtro de atividade: tipo do subject (basename da classe). | Individual |
subject_id | Não | Filtro de atividade: id do subject. | 12 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
taxon_root | Não | Id/nome de taxon incluindo descendentes. | Lauraceae |
voucher | Não | Id do voucher para filtrar measurements. | 102 |
Campos retornados
Campos (simple): id, log_name, description, subject_type, subject_name, subject_id, modified_by, properties, created_at, updated_at
Campos (all): id, log_name, description, subject_type, subject_id, subject_name, modified_by, properties, created_at, updated_at
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"field_key": "taxon_id",
"field": "Taxon",
"old_value": "Burseraceae",
"new_value": "Protium hebetatum forma.b.fito",
"id": 1411696,
"log_name": "individual",
"description": "identification updated",
"subject_type": "App\\Models\\Individual",
"subject_id": 301705,
"subject_name": null,
"modified_by": "example"
},
{
"field_key": "person_id",
"field": "Person",
"old_value": "Macedo, M.T.S",
"new_value": "Pilco, M.V.",
"id": 1411696,
"log_name": "individual",
"description": "identification updated",
"subject_type": "App\\Models\\Individual",
"subject_id": 301705,
"subject_name": null,
"modified_by": "example"
},
{
"field_key": "notes",
"field": "Notes",
"old_value": "Identificação feita em campo, anotada na planilha de dados.",
"new_value": null,
"id": 1411696,
"log_name": "individual",
"description": "identification updated",
"subject_type": "App\\Models\\Individual",
"subject_id": 301705,
"subject_name": null,
"modified_by": "example"
},
{
"field_key": "date",
"field": "Date",
"old_value": "2022-06-17",
"new_value": "2022-11-23",
"id": 1411696,
"log_name": "individual",
"description": "identification updated",
"subject_type": "App\\Models\\Individual",
"subject_id": 301705,
"subject_name": null,
"modified_by": "example"
}
]
}tags (GET)
Tags/palavras-chave (GET lista).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. | 1,2,3 |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
fields | Não | Lista separada por vírgulas dos campos a serem incluídos na resposta ou uma palavra especial all/simple/raw, padrão: simple | id,scientificName ou all |
job_id | Não | Id do job para reutilizar affected_ids ou filtrar resultados. | 1024 |
language | Não | Id/código/nome do idioma | en ou 1 ou english ou portugues ou pt-br |
limit | Não | Quantidade maxima de registros retornados. | 100 |
name | Não | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
offset | Não | A posição inicial do conjunto de registros a ser exportado. Usado em conjunto com limit para limitar os resultados. | 10000 |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
save_job | Não | Se 1, salva a consulta como job para baixar depois via userjobs + get_file = 1 | 1 |
search | Não | Parametro de busca de texto. | Silva |
trait | Não | Id ou export_name do trait para filtro. | DBH |
Campos retornados
Campos (simple): id, name, description
Campos (all): id, name, description, counts
Exemplo de resposta
{
"meta": {
"odb_version": "0.10.0-alpha1",
"api_version": "v0",
"server": "http://localhost/opendatabio"
},
"data": [
{
"id": 11,
"name": "Folhas adaxial",
"description": "Images of the adaxial surface of leaves",
"counts": {
"Media": 1852,
"Project": 0,
"Dataset": 0,
"ODBTrait": 0
}
},
{
"id": 12,
"name": "Folha forma",
"description": "Imagem mostrando uma folha ou o formato da folha.",
"counts": {
"Media": 713,
"Project": 0,
"Dataset": 0,
"ODBTrait": 0
}
},
{
"id": 13,
"name": "Frutos",
"description": "Imagens com frutos",
"counts": {
"Media": 2595,
"Project": 0,
"Dataset": 0,
"ODBTrait": 0
}
}
]
}3.3 - Inserir dados - POST
Importando dados
- O pacote OpenDataBio é um cliente para esta API e permite importar dados a partir de objetos da linguagem R (exemplos);
- Dados podem ser importados via interface web através de planilhas, onde os nomes das colunas são Parâmetros POST listados nesta página
- O token de autenticação é necessário para solicitações POST
Dados estruturados perzonalizados no campo notes
No campo notes de qualquer modelo, você pode armazenar texto simples ou um texto formatado como um objeto JSON contendo dados estruturados. A opção Json permite que você armazene dados estruturados personalizados em qualquer modelo que tenha o campo notes. Esses dados não serão validados pelo OpenDataBio e a padronização de tags e valores depende de você.
Endpoints POST
Links rápidos
- bibreferences
- biocollections
- individuals
- individual-locations
- locations
- locations-validation
- measurements
- media
- persons
- taxons
- traits
- vernaculars
- vouchers
- datasets
bibreferences (POST)
Referências bibliográficas (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
bibtex | Não | Referência em formato BibTeX. (Provide doi or bibtex.) | @article{meuchave,...} |
doi | Não | Número ou URL de DOI. (Provide doi or bibtex.) | 10.1234/abcd.2020.1 |
biocollections (POST)
Biocoleções (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
acronym | Sim | Sigla da biocoleção. | INPA |
name | Sim | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
individuals (POST)
Indivíduos (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
altitude | Não | Altitude em metros. | 75 |
angle | Não | Azimute em graus a partir do ponto de referência. | 45 |
biocollection | Não | Id, nome ou sigla da biocoleção. | INPA |
biocollection_number | Não | Número/código do voucher na biocoleção. | 12345 |
biocollection_type | Não | Código ou nome do tipo nomenclatural. | Holotype ou 2 |
collector | Sim | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Sim | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Sim | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. (At least the year must be provided.) | 2024-05-20 ou {\"year\":1888,\"month\":5} |
distance | Não | Distância ao ponto de referência em metros. | 12.5 |
identification_based_on_biocollection | Não | Nome/id da biocoleção usada como referência de identificacao. | INPA |
identification_based_on_biocollection_number | Não | O catalogNumber do voucher usado como referência. | 8765 |
identification_date | Não | Data da identificacao (completa ou incompleta). | 2023-06-NA |
identification_individual | Não | Id/organismID do indivíduo cuja identificacao sera reaproveitada. | 3245 ou REC-123 |
identification_notes | Não | Notas da identificacao. | Conferido em microscopia |
identifier | Não | Pessoa(s) responsavel(is) pela identificacao; aceita id, abreviação, nome ou email; use | ou ;. | A.Costa|B.Lima |
latitude | Não | Latitude em graus decimais (negativo para sul). (Required when location is not provided.) | -3.101 |
location | Não | Id ou nome do local. (Required when latitude/longitude are not provided.) | Parcela 25ha ou 55 |
location_date_time | Não | Data ou data+hora do evento de localização/ocorrência. (Required when adding multiple locations or when different from individual date.) | 2023-08-14 12:30:00 |
location_notes | Não | Notas da ocorrência/local. | Perto do marco 10 |
longitude | Não | Longitude em graus decimais (negativo para oeste). (Required when location is not provided.) | -60.12 |
modifier | Não | Código/nome do modificador de identificacao (s.s.=1, s.l.=2, cf.=3, aff.=4, vel aff.=5). | 3 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
tag | Sim | Tag/número/código do indivíduo. | A-1234 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
x | Não | Coordenada X para plots ou posicao de indivíduo. | 12.3 |
y | Não | Coordenada Y para plots ou posicao de indivíduo. | 8.7 |
individual-locations (POST)
Ocorrências para indivíduos com múltiplas localizações (GET lista, POST/PUT grava).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
altitude | Não | Altitude em metros. | 75 |
angle | Não | Azimute em graus a partir do ponto de referência. | 45 |
distance | Não | Distância ao ponto de referência em metros. | 12.5 |
individual | Sim | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
latitude | Não | Latitude em graus decimais (negativo para sul). (Required when location is not provided.) | -3.101 |
location | Não | Id ou nome do local. (Required when latitude/longitude are not provided.) | Parcela 25ha ou 55 |
location_date_time | Sim | Data ou data+hora do evento de localização/ocorrência. | 2023-08-14 12:30:00 |
location_notes | Não | Notas da ocorrência/local. | Perto do marco 10 |
longitude | Não | Longitude em graus decimais (negativo para oeste). (Required when location is not provided.) | -60.12 |
x | Não | Coordenada X para plots ou posicao de indivíduo. | 12.3 |
y | Não | Coordenada Y para plots ou posicao de indivíduo. | 8.7 |
locations (POST)
Localidades (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
adm_level | Sim | Código do nível administrativo do local (ex. 100=parcela, 10=país). | 100 |
altitude | Não | Altitude em metros. | 75 |
azimuth | Não | Azimute (graus) usado para montar geometria de plot/transecto quando o local e POINT. | 90 |
datum | Não | Datum/projecao espacial. | EPSG:4326-WGS 84 |
geojson | Não | Feature GeoJSON unica com geometria e pelo menos name + adm_level nas properties. | {\"type\":\"Feature\",\"properties\":{\"name\":\"Plot A\",\"adm_level\":100},\"geometry\":{...}} |
geom | Não | Geometria WKT (POINT, LINESTRING, POLYGON, MULTIPOLYGON). (Provide geom or lat+long.) | POLYGON((-60 -3,-60.1 -3,-60.1 -3.1,-60 -3.1,-60 -3)) |
ismarine | Não | Flag para aceitar locais marinhos fora de poligonos de país. | 1 |
lat | Não | Latitude em graus decimais (negativo para sul). (Provide geom or lat+long.) | -3.101 |
long | Não | Longitude em graus decimais (negativo para oeste). (Provide geom or lat+long.) | -60.12 |
name | Sim | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
parent | Não | Id ou nome do pai (taxon ou local). | Lauraceae ou 210 |
startx | Não | Coordenada X inicial de subparcela em relação ao plot pai. | 5.5 |
starty | Não | Coordenada Y inicial de subparcela em relação ao plot pai. | 10.0 |
x | Não | Coordenada X para plots ou posicao de indivíduo. | 12.3 |
y | Não | Coordenada Y para plots ou posicao de indivíduo. | 8.7 |
locations-validation (POST)
Valida coordenadas com locais registrados (POST).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
latitude | Sim | Latitude em graus decimais (negativo para sul). | -3.101 |
longitude | Sim | Longitude em graus decimais (negativo para oeste). | -60.12 |
measurements (POST)
Medições de traits (GET lista, POST cria via job de importação, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
bibreference | Não | Id ou bibkey da referência. | 34 |
dataset | Sim | ID/nome do dataset onde a medição será armazenada; se omitido, usa o dataset padrão do usuário autenticado se existir. | 3 ou FOREST1 |
date | Sim | Data da medição; aceita YYYY-MM-DD, YYYY-MM, YYYY, ou campos em array ano-mês-dia (date_year/date_month/date_day). | 2024-05-10 ou 2024-05 ou {"year":2024,"month":5} |
duplicated | Não | Número sequencial para permitir medidas duplicadas do mesmo trait/objeto/data. | 2 para o segundo registro, 3 para o terceiro e assim por diante |
link_id | Não | Obrigatório para traços do tipo LINK: ID do objeto ligado (ex.: ID do Taxon). (Required when trait type is Link.) | 55 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
notes | Não | Opcional. Texto livre ou notas em JSON armazenadas com a medição. | {"method":"caliper"} |
object_id | Sim | Obrigatório. ID numérico do objeto medido (Individual, Location, Taxon, Voucher, Media). Alias: measured_id. | 4521 |
object_type | Sim | Obrigatório quando não fornecido no header. Nome da classe ou FQCN do objeto medido (Individual, Location, Taxon, Voucher, Media). Alias: measured_type. | Individual |
parent_measurement | Não | Quando a variável depende de outra medição, informe o ID da medição pai para o mesmo objeto e data. | 3001 |
person | Sim | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). | Silva, J.B.|Costa, M. |
trait_id | Sim | Obrigatório. ID ou export_name da variável medida. Alias: também aceita chave “trait”. | treeDbh ou 12 |
value | Não | Valor(es) da medida; depende do tipo do trait: QUANT_INTEGER (0) = número inteiro; QUANT_REAL (1) = número decimal, ponto como separator; CATEGORICAL or ORDINAL (2/4) = uma única categoria, pode ser o id ou o nome; CATEGORICAL_MULTIPLE (3) = lista de ids ou nomes de categorias separadas por | ; ou ,; TEXT (5) = um texto livre; COLOR (6) = cor em formato hex #A1B2C3 or #ABC; LINK (7) = enviar o link_id do object (value pode ser vazio neste caso, ou um número); SPECTRAL (8) = valores de absorbânica/reflectância separados por ponto-e-vírgula (;) com mesmo número de valores especificados na definição da variável; GENEBANK (9) = código alfanumérico do accesso do registro no GenBank (ele é validado contra o NCBI). (Required unless trait type is Link.) | QUANT_REAL: 23.4 | CATEGORICAL: 15 ou Morta | CATEGORICAL_MULTIPLE: 12;14 ou Simples;Composta | SPECTRAL: 0.12;0.11;0.10 |
media (POST)
Metadados de mídia (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
collector | Não | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Não | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. | 2024-05-20 ou {\"year\":1888,\"month\":5} |
filename | Sim | Nome exato do arquivo de mídia dentro do ZIP ao importar mídia. | IMG_0001.jpg |
latitude | Não | Latitude em graus decimais (negativo para sul). | -3.101 |
license | Não | Licenca publica para mídia (CC0, CC-BY, CC-BY-SA, etc.). | CC-BY-SA |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
longitude | Não | Longitude em graus decimais (negativo para oeste). | -60.12 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
object_id | Sim | ID do objeto ao qual a mídia pertence (Indivíduo, Local, Táxon, Voucher). | 4521 |
object_type | Sim | O tipo de objeto ao qual a mídia pertence, um dos seguintes: Individual, Local, Táxon, Voucher ou Media. | Individual |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
tags | Não | Ids ou nomes de tags para mídia ou filtros (use | ou ;). | flower|leaf |
title_en | Não | Titulo da mídia em ingles. | Leaf detail |
title_pt | Não | Titulo da mídia em portugues. | Detalhe da folha |
persons (POST)
Pessoas (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
abbreviation | Não | Abreviação padrão de pessoa ou coleção. | Silva, J.B. |
biocollection | Não | Id, nome ou sigla da biocoleção. | INPA |
email | Não | Endereco de email. | user@example.org |
full_name | Sim | Nome completo da pessoa. | Joao Silva |
institution | Não | Instituicao associada a pessoa. | INPA |
taxons (POST)
Nomes taxonômicos (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
author | Não | Autor do nome taxonômico (para nomes não publicados). | Smith & Jones |
author_id | Não | Id/nome/email da pessoa autora de nome não publicado. (Required for unpublished names (or use person).) | 25 |
bibreference | Não | Id ou bibkey da referência. | 34 |
gbif | Não | nubKey do GBIF para taxon. | 28792 |
ipni | Não | Id IPNI para taxon. | 123456-1 |
level | Não | Código ou string do nível taxonômico. | 210 ou species |
mobot | Não | Id do Tropicos para taxon. | 12345678 |
mycobank | Não | Id MycoBank para taxon. | MB123456 |
name | Sim | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
parent | Não | Id ou nome do pai (taxon ou local). (Required for unpublished names.) | Lauraceae ou 210 |
person | Não | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). (Required for unpublished names (or use author_id).) | Silva, J.B.|Costa, M. |
valid | Não | Quando 1 retorna apenas nomes taxonômicos validos. | 1 |
zoobank | Não | Id ZooBank para taxon. | urn:lsid:zoobank.org:act:12345678 |
traits (POST)
Definições de traits (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
bibreference | Não | Id ou bibkey da referência. | 34 |
categories | Não | Lista JSON de categorias de trait com lang/rank/name/description. (Required for categorical and ordinal traits.) | [{\"lang\":\"en\",\"rank\":1,\"name\":\"small\"}] |
description | Sim | Descrição em texto ou mapa de traducao. | {\"en\":\"Leaf length\",\"pt-br\":\"Comprimento da folha\"} |
export_name | Sim | Nome de exportação unico do trait. | DBH |
link_type | Não | Classe alvo do trait tipo Link (ex. Taxon). (Required for Link traits.) | Taxon |
name | Sim | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
objects | Sim | Objetos alvo do trait (separados por virgula). | Individual,Voucher |
parent | Não | ID da característica pai ou nome de exportação; quando definido, as medições desta característica também devem incluir uma medição para a característica pai. | woodDensity |
range_max | Não | Valor máximo permitido para traits quantitativos. | 999.9 |
range_min | Não | Valor mínimo permitido para traits quantitativos. | 0.01 |
tags | Não | Ids ou nomes de tags para mídia ou filtros (use | ou ;). | flower|leaf |
type | Sim | Parametro generico type (código do trait ou tipo de vernacular: use/generic/etimology). | use ou 10 |
unit | Não | (Required for quantitative traits.) | — |
value_length | Não | Número de valores para trait espectral. (Required for spectral traits.) | 1024 |
wavenumber_max | Não | Número de onda máximo para traits espectrais. (Required for spectral traits.) | 25000 |
wavenumber_min | Não | Número de onda mínimo para traits espectrais. (Required for spectral traits.) | 4000 |
vernaculars (POST)
Nomes vernáculos (GET lista, POST cria).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
citations | Não | Lista de citacoes (texto + bibreference) para vernaculares. | [{\"citation\":\"Silva 2020\",\"bibreference\":12}] |
individuals | Não | Lista de ids/nomes de indivíduos para vincular vernacular. | 12|23|45 |
language | Sim | Id/código/nome do idioma | en ou 1 ou english ou portugues ou pt-br |
name | Sim | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
parent | Não | Id ou nome do pai (taxon ou local). | Lauraceae ou 210 |
taxons | Não | Lista de ids/nomes de taxon (para vernacular). | Euterpe edulis|Ocotea guianensis |
type | Não | Parametro generico type (código do trait ou tipo de vernacular: use/generic/etimology). | use ou 10 |
vouchers (POST)
Vouchers de coleção (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
biocollection | Sim | Id, nome ou sigla da biocoleção. | INPA |
biocollection_number | Não | Número/código do voucher na biocoleção. | 12345 |
biocollection_type | Não | Código ou nome do tipo nomenclatural. | Holotype ou 2 |
collector | Não | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Não | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. | 2024-05-20 ou {\"year\":1888,\"month\":5} |
individual | Sim | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
number | Não | Número/código de coletor (voucher ou tag quando diferente). | 1234A |
datasets (POST)
Datasets e arquivos de versões publicadas (GET lista, POST cria via job de importação).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
description | Não | Descrição em texto ou mapa de traducao. (Required when privacy is 2 or 3.) | {\"en\":\"Leaf length\",\"pt-br\":\"Comprimento da folha\"} |
license | Não | Licenca publica para mídia (CC0, CC-BY, CC-BY-SA, etc.). (Required when privacy is 2 or 3.) | CC-BY-SA |
name | Sim | Short name or nickname for the dataset - make informative, shorter than title. | Morphometrics-Aniba |
privacy | Sim | (Accepted values: 0 (auth), 1 (project), 2 (registered), 3 (public).) | — |
project_id | Não | (Required when privacy is 1 (project).) | — |
title | Não | (Required when privacy is 2 or 3.) | — |
3.4 - Atualizar dados - PUT
Somente os endpoints listados abaixo podem ser atualizados usando a API e somente os campos PUT listados podem ser atualizados em cada endpoint. Os valores dos campos são os mesmos como explicados para a API POST, exceto que em todos os casos o id do registro a ser atualizado também deve ser fornecido.
Links rápidos
individuals (PUT)
Indivíduos (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | ID numérico do registro a ser atualizado (Provide id or individual_id.) | 12 |
collector | Não | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Não | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. | 2024-05-20 ou {\"year\":1888,\"month\":5} |
identification_based_on_biocollection | Não | Nome/id da biocoleção usada como referência de identificacao. | INPA |
identification_based_on_biocollection_number | Não | O catalogNumber do voucher usado como referência. | 8765 |
identification_date | Não | Data da identificacao (completa ou incompleta). | 2023-06-NA |
identification_individual | Não | Id/organismID do indivíduo cuja identificacao sera reaproveitada. | 3245 ou REC-123 |
identification_notes | Não | Notas da identificacao. | Conferido em microscopia |
identifier | Não | Pessoa(s) responsavel(is) pela identificacao; aceita id, abreviação, nome ou email; use | ou ;. | A.Costa|B.Lima |
individual_id | Não | ID numérico do registro a ser atualizado (Provide id or individual_id.) | 12 |
modifier | Não | Código/nome do modificador de identificacao (s.s.=1, s.l.=2, cf.=3, aff.=4, vel aff.=5). | 3 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
tag | Não | Tag/número/código do indivíduo. | A-1234 |
taxon | Não | Id ou nome canônico do taxon (lista aceita). | Licaria cannela,Licaria armeniaca ou 456,789 |
individual-locations (PUT)
Ocorrências para indivíduos com múltiplas localizações (GET lista, POST/PUT grava).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | ID numérico do registro a ser atualizado (Provide id or individual_location_id.) | 12 |
altitude | Não | Altitude em metros. | 75 |
angle | Não | Azimute em graus a partir do ponto de referência. | 45 |
distance | Não | Distância ao ponto de referência em metros. | 12.5 |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
individual_location_id | Não | Id de individual-location para atualizacao. (Provide id or individual_location_id.) | 44 |
latitude | Não | Latitude em graus decimais (negativo para sul). | -3.101 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
location_date_time | Não | Data ou data+hora do evento de localização/ocorrência. | 2023-08-14 12:30:00 |
location_notes | Não | Notas da ocorrência/local. | Perto do marco 10 |
longitude | Não | Longitude em graus decimais (negativo para oeste). | -60.12 |
x | Não | Coordenada X para plots ou posicao de indivíduo. | 12.3 |
y | Não | Coordenada Y para plots ou posicao de indivíduo. | 8.7 |
locations (PUT)
Localidades (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | ID numérico do registro a ser atualizado (Provide id or location_id.) | 12 |
adm_level | Não | Código do nível administrativo do local (ex. 100=parcela, 10=país). | 100 |
altitude | Não | Altitude em metros. | 75 |
datum | Não | Datum/projecao espacial. | EPSG:4326-WGS 84 |
geom | Não | Geometria WKT (POINT, LINESTRING, POLYGON, MULTIPOLYGON). | POLYGON((-60 -3,-60.1 -3,-60.1 -3.1,-60 -3.1,-60 -3)) |
ismarine | Não | Flag para aceitar locais marinhos fora de poligonos de país. | 1 |
lat | Não | Latitude em graus decimais (negativo para sul). | -3.101 |
location_id | Não | Id do local a atualizar. (Provide id or location_id.) | 44 |
long | Não | Longitude em graus decimais (negativo para oeste). | -60.12 |
name | Não | Parametro generico de nome (taxon completo, local, export_name de trait, etc.). | Ocotea guianensis |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
parent | Não | Id ou nome do pai (taxon ou local). | Lauraceae ou 210 |
startx | Não | Coordenada X inicial de subparcela em relação ao plot pai. | 5.5 |
starty | Não | Coordenada Y inicial de subparcela em relação ao plot pai. | 10.0 |
x | Não | Coordenada X para plots ou posicao de indivíduo. | 12.3 |
y | Não | Coordenada Y para plots ou posicao de indivíduo. | 8.7 |
measurements (PUT)
Medições de traits (GET lista, POST cria via job de importação, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | ID numérico do registro a ser atualizado (Provide id or measurement_id.) | 12 |
bibreference | Não | Id ou bibkey da referência. | 34 |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Não | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. | 2024-05-20 ou {\"year\":1888,\"month\":5} |
duplicated | Não | Número sequencial para permitir medidas duplicadas do mesmo trait/objeto/data. | 2 para o segundo registro, 3 para o terceiro e assim por diante |
link_id | Não | Id do objeto ligado quando o trait e do tipo Link. | id do taxon 55 |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
measurement_id | Não | Id de measurement para atualizacao. (Provide id or measurement_id.) | 77 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
object_id | Não | Id do objeto medido (Individual, Location, Taxon, Voucher ou Media). | 4521 |
object_type | Não | Tipo do objeto medido: Individual, Location, Taxon, Voucher ou Media. | Individual |
parent_measurement | Não | Id de measurement pai. | 3001 |
person | Não | Id/abreviação/nome/email de pessoa (aceita lista com | ou ;). | Silva, J.B.|Costa, M. |
trait_id | Não | Id ou export_name do trait para measurements. | 12 ou DBH |
value | Não | Valor(es) da medida; depende do tipo do trait: QUANT_INTEGER (0) = número inteiro; QUANT_REAL (1) = número decimal, ponto como separator; CATEGORICAL or ORDINAL (2/4) = uma única categoria, pode ser o id ou o nome; CATEGORICAL_MULTIPLE (3) = lista de ids ou nomes de categorias separadas por | ; ou ,; TEXT (5) = um texto livre; COLOR (6) = cor em formato hex #A1B2C3 or #ABC; LINK (7) = enviar o link_id do object (value pode ser vazio neste caso, ou um número); SPECTRAL (8) = valores de absorbânica/reflectância separados por ponto-e-vírgula (;) com mesmo número de valores especificados na definição da variável; GENEBANK (9) = código alfanumérico do accesso do registro no GenBank (ele é validado contra o NCBI). | QUANT_REAL: 23.4 | CATEGORICAL: 15 ou Morta | CATEGORICAL_MULTIPLE: 12;14 ou Simples;Composta | SPECTRAL: 0.12;0.11;0.10 |
media (PUT)
Metadados de mídia (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | Id unico ou lista separada por virgula para filtrar/selecionar registros. (Provide id, media_id or media_uuid.) | 1,2,3 |
collector | Não | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Não | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. | 2024-05-20 ou {\"year\":1888,\"month\":5} |
latitude | Não | Latitude em graus decimais (negativo para sul). | -3.101 |
license | Não | Licenca publica para mídia (CC0, CC-BY, CC-BY-SA, etc.). | CC-BY-SA |
location | Não | Id ou nome do local. | Parcela 25ha ou 55 |
longitude | Não | Longitude em graus decimais (negativo para oeste). | -60.12 |
media_id | Não | Id numerico de mídia. (Provide id, media_id or media_uuid.) | 88 |
media_uuid | Não | UUID da mídia. (Provide id, media_id or media_uuid.) | a3f0a4ac-6b5b-11ed-b8c0-0242ac120002 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
project | Não | Id ou sigla do projeto. | PDBFF ou 2 |
tags | Não | Ids ou nomes de tags para mídia ou filtros (use | ou ;). | flower|leaf |
title_en | Não | Titulo da mídia em ingles. | Leaf detail |
title_pt | Não | Titulo da mídia em portugues. | Detalhe da folha |
persons (PUT)
Pessoas (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | ID numérico do registro a ser atualizado (Provide id or person_id.) | 12 |
abbreviation | Não | Abreviação padrão de pessoa ou coleção. | Silva, J.B. |
biocollection | Não | Id, nome ou sigla da biocoleção. | INPA |
email | Não | Endereco de email. | user@example.org |
full_name | Não | Nome completo da pessoa. | Joao Silva |
institution | Não | Instituicao associada a pessoa. | INPA |
person_id | Não | Id da pessoa a atualizar. (Provide id or person_id.) | 12 |
vouchers (PUT)
Vouchers de coleção (GET lista, POST cria, PUT atualiza).
| Parâmetro | Obrigatório | Descrição | Exemplo |
|---|---|---|---|
id | Não | ID numérico do registro a ser atualizado (Provide id or voucher_id.) | 12 |
biocollection | Não | Id, nome ou sigla da biocoleção. | INPA |
biocollection_number | Não | Número/código do voucher na biocoleção. | 12345 |
biocollection_type | Não | Código ou nome do tipo nomenclatural. | Holotype ou 2 |
collector | Não | Coletor(es) id, abreviação, nome ou email. Separe múltiplos com | ou ;, primeiro e o principal. | Silva, J.B.|Costa, M. |
dataset | Não | Id ou sigla do dataset. | 3 ou FOREST1 |
date | Não | Data (AAAA-MM-DD) ou data incompleta (ex. 1888-05-NA) ou array com year/month/day. | 2024-05-20 ou {\"year\":1888,\"month\":5} |
individual | Não | Id, uuid ou organismID do indivíduo. | 4521 ou 2ff0e884-3d33 |
notes | Não | Notas em texto ou JSON. | {\"expedition\":\"2024-01\",\"tag\":\"P1\"} |
number | Não | Número/código de coletor (voucher ou tag quando diferente). | 1234A |
voucher_id | Não | Id do voucher a atualizar. (Provide id or voucher_id.) | 55 |
4 - Modelo conceitual
4.1 - Objetos Centrais
Os objetos centrais são: Localidades, Vouchers, Indivíduos, Taxons e Arquivos de Mídia. Essas entidades são consideradas “centrais” porque podem receber Medições, ou seja, você pode registrar valores para qualquer Variável.
O objeto Indivíduo refere-se a um organismo individual que foi observado uma vez (uma ocorrência) ou foi marcado para monitoramento, como uma árvore em uma parcela permanente, uma ave anilhada, um morcego rastreado por rádio. Os indivíduos podem ter um ou mais Vouchers em uma BioColeção e um ou vários Localidades e terão uma Identificação taxonômica. Qualquer atributo medido ou tomado para um individuo pode ser associado a este objeto por meio do modelo Medição.
O objeto Vouchers é para registros de espécimes coletados de Indivíduo e depositados em uma BioColeção. A identificação taxonômica e a localização de um voucher é aquela do próprio indivíduo a que pertence. Medições podem ser vinculadas a um Voucher quando você deseja registrar explicitamente os dados para aquela amostra específica (por exemplo, medições morfológicas; um marcador molecular de uma extração de uma amostra em um coleta de tecido). Caso contrário, você pode simplesmente registrar a medição para o indivíduo ao qual o voucher pertence. O modelo de voucher também está disponível como tipo especial de Variável, o
LinkType, tornando possível registrar contagens para o táxon do voucher em um determinado local.O objeto Localidades contém geometrias espaciais, como pontos e polígonos, e inclui
parcelasetransectoscomo casos especiais. Um Indivíduo pode ter uma localidade (por exemplo, uma planta) ou multiplas localidades (por exemplo, um animal monitorado). As localidades do tipo PARCELA e TRANSECTO podem ser registradas como geometria espacial ou apenas com geometria de ponto, e podem ter dimensões cartesianas (metros) registradas. Os indivíduos também podem ter posições cartesianas (X e Y ou angle e distance) em relação à sua Localidade, permitindo contabilizar o mapeamento tradicional de indivíduos em unidades de amostragem. Medições ecológicas relevantes, como dados de solo ou clima, são exemplos de Medições que podem ser vinculadas a localidades.O objeto Taxon, além de seu uso para a Identificação taxonômica de Indivíduos, pode receber Medições, permitindo a organização de dados secundários publicados ou qualquer tipo de informação ligada a um nome taxonômico. Uma Referência Bibliográfica pode ser incluída para indicar a fonte de dados. Além disso, o modelo Taxon está disponível como tipo especial de Variável, o
LinkType, tornando possível registrar contagens de Taxons em um determinado local.
Localidades
O modelo Localidades armazena dados que representam locais do mundo real. Eles podem ser países, cidades, unidades de conservação ou qualquer polígono espacial, ponto ou trilha na superfície da Terra. Esses objetos são hierárquicos e possuem um relacionamento pai-filho implementado pelo Nested Set Model para dados hierárquicos da biblioteca Laravel Baum que facilita tanto a validação quanto as consultas.
Tipos de Localidades especiais são parcelas e transectos, que juntamente com pontos permitem diferentes métodos de amostragem usados em estudos de biodiversidade. Esses tipos de Localidades também podem ser vinculados a uma localidade administrativa pai e, além disso, a três tipos adicionais de localidades pai como Unidades de Conservação, Territórios Indígenas e qualquer camada Ambiental representando classes de vegetação, classes de solo , etc … com geometrias espaciais definidas.
Tabela locations
- As colunas
parent_idjunto comrgt,lftedephsão usadas para definir o modelo de conjunto aninhado para consultar ancestrais e descendentes de forma rápida. Apenasparent_idé especificado pelo usuário, as outras colunas são calculadas pela biblioteca Baum a partir dos valores id+parent_id que definem a hierarquia. O mesmo modelo hierárquico é usado para o Taxons, mas para locais há uma restrição espacial, ou seja, um filho deve estar dentro de uma geometria pai. - A coluna
adm_levelindica o nível administrativo, ou tipo, de localidade. Por padrão, os seguintesadm_levelsão configurados no OpenDataBio:2para o país,3para a primeira divisão dentro do país (província, estado),4para a segunda divisão (por exemplo, município), … atéadm_level = 10como áreas administrativas (o código do país é 2 para permitir a padronização com OpenStreeMaps, que é recomendado seguir se sua instalação incluir dados de diferentes países). Os níveis administrativos podem ser configurados em um OpenDataBio antes de importar quaisquer dados para o banco de dados, consulte o guia de instalação para obter detalhes sobre isso.99é o código para Unidades de Conservação - uma unidade de conservação é umalocationque pode estar vinculada a vários outros locais (qualquer local pode pertencer a uma única UC). Assim, uma localidade pode ter como pai um município e como uc a unidade de conservação a que pertence.98é o código para Territórios Indígenas - mesmas propriedades das Unidades de Conservação, mas tratadas separadamente apenas porque algumas UCs e TIs podem se sobrepor amplamente como é o caso da região amazônica97é o código para Camadas ambientais - mesmas propriedades das Unidades de Conservação e Territórios Indígenas, ou seja, podem ser vinculadas como localidade pai adicional a qualquer Ponto, Parcela ou Transecto e, portanto, seus indivíduos relacionados. Armazene polígonos e geometrias de multipolígonos representando classes ambientais, como unidades de vegetação, biomas, classes de solo, etc …100é o código paraparcelasesub-parcelas- as localidades de tipo parcelas podem ser registradas com geometria de ponto ou polígono, e também devem ter dimensões cartesianas associadas em metros. Se for uma localização de ponto, a geometria é definida a partir do ponto informado. As dimensões cartesianas de uma localidade de tipo parcela também podem ser combinadas com posições cartesianas de subparcelas (ou seja, uma localidade de parcela cujo pai também é uma localidade de parcela) e/ou de indivíduos dentro de tais parcelas, permitindo que indivíduos e subparcelas sejam mapeados dentro de uma subparcela sem especificações de geometria. Em outras palavras, se a geometria espacial da Parcela for desconhecida, ela pode ter como geometria um único ponto GPS ao invés de um polígono, mais suas dimensõesxey. Uma subparcela é uma parcela cuja localidade pai também é uma parcela, e deve consistir em um ponto marcando o início da subparcela mais suas dimensões cartesianas X e Y. Se a geometria do início da subplot for subparcela, ela pode ser armazenada como uma posição relativa à parcela pai usandostartxestarty.101para transectos - como parcelas, os transectos podem ser registrados tendo uma geometria LineString ou simplesmente uma única coordenada de Latitude e Longitude e uma dimensão. A dimensão cartesianaxpara transectos representa o comprimento em metros e é usada para criar linha (orientada para o Norte) quando apenas um ponto é informado. A dimensãoyé usada para validar os indivíduos como pertencentes à uma localidade do tipo transecto e representa a distância máxima da linha que um indivíduo deve cair para ser detectado naquele local.999para localidades ‘POINT’ como waypoints GPS - isto é para registro de qualquer ponto no espaço
- A coluna
datumpode registrar a propriedade do datum da geometria, se conhecida. Se deixado em branco, o local é considerado armazenado usando o datum WGS84. Porém, não há conversor embutido de outros tipos de dados. Portanto os mapas exibidos podem ficar incorretos se diferentes projeções forem usadas. Fortemente recomendado projetar dados como WSG84 para padronização. - A coluna
geomarmazena a geometria da localização no banco de dados, permitindo consultas espaciais em linguagem SQL, comodetecção das localidades pai. A geometria de um local pode serPOINT,POLYGON,MULTIPOLYGONouLINESTRINGe deve ser formatada usando Well-Known-Text representação geométrica da localidade. Quando um POLYGON é informado, o primeiro ponto dentro da string geométrica é privilegiado, ou seja, pode ser utilizado como referência para marcações relativas. Por exemplo, tal ponto será a referência para as colunasstartxestartyde uma subparcela. Portanto, para as geometriasplotetransect, importa qual ponto é listado primeiro na geometria WKT
Acesso a dados usuários completos podem registrar novas Localidades, editar detalhes de Localidades e remover registros de Localidades que não têm dados associados. As Localidades têm acesso público.
Indivíduos
O objeto Indivíduo representa um registro para um organismo individual. Pode ser uma única ocorrência no espaço-tempo de um animal, planta ou fungo, ou um indivíduo monitorado ao longo do tempo, como uma planta em parcela florestal permanente, ou um animal de captura-recaptura ou rádio-rastreamento.
Um Indivíduo pode ter um ou mais Vouchers representando amostras físicas do indivíduo armazenadas em uma ou mais BioColeção e pode ter um ou mais Localidades, representando o local ou locais onde o indivíduo foi registrado.
Indivíduos também podem ter uma Identificação taxonômica, que pode ser própria ou pode depender da identificação de outro indivíduo (identificação-dependente). A identificação é herdada por todos os Vouchers registrados para o Indivíduo. Portanto, os vouchers não têm sua identificação própria. A tabela de Identificações agora referencia sempre individual_id (sem relacionamento polimórfico), e os identificadores são vinculados via pivô identification_person.
Tabela individuals
- Um registro de um Indivíduo deve especificar pelo menos uma Localidade onde foi registrado, a
datedo registro, o identificador localtage ocollectorsdo registro e odatasetao qual o indivíduo pertence. - A localidade pode ser qualquer localidade cadastrado, independente do nível, permitindo armazenar registros históricos cujo georreferenciamento é apenas um local administrativo. Localidades são armazenadas na tabela
individual_location, tendo colunasdate_time,altitude,noteserelative_position. - A coluna
relative_positionarmazena as coordenadas cartesianas do Indivíduo em relação à sua localidade. Isso é apenas para indivíduos localizados em locais do tipoplot,transectoupoint. Por exemplo, uma parcela com dimensões de 100x100 metros (1ha) pode ter um indivíduo composição relativa = PONTO (50 50), que colocará o indivíduo no centro do local (isso é mostrado graficamente na interface da web conforme definido pelas coordenadasxeydo indivíduo). Se a localidade for uma subparcela, a posição dentro da parcela pai também pode ser calculada (isso foi projetado com as parcelas do ForestGeo em mente e é uma coluna na API individual GET. Se a localidade for um PONTO, a posição_relativa pode ser informada comoangle(= azimute) edistance, atributos frequentemente medidos em métodos de amostragem. Se a localidade for um TRANSECT, a posição_relativa posiciona o indivíduo em relação à linha, sendoxa distância ao longo do transecto a partir do primeiro ponto, e oya distância perpendicular onde o indivíduo está localizado, também levando em consideração alguns métodos de amostragem; - O campo
datenos modelos Indivíduo, Voucher, Medição e Identificação pode ser uma Data Incompleta, ou seja, apenas o ano ou ano + mês podem ser registrados. - A tabela Collector representa os coletores para um indivíduo ou voucher e está vinculada ao Modelo de pessoa. A tabela de coletores possui uma relação polimórfica com os objetos Voucher e Individual, definidos pelas colunas
object_ideobject_type, permitindo múltiplos coletores para cada registro individual ou voucher. O main_collector indicado é apenas o primeiro coletor listado para essas entidades. - O campo
tagé um código identificador para o indivíduo. Pode ser o número escrito na etiqueta de alumínio de uma árvore em uma parcela florestal, o número de uma anilha numa ave, ou onúmero de coletorde um espécime. A combinação demain_collector+tag+first_locationé restrita a ser única no OpenDataBio. A identificação taxonômica de um indivíduo pode ser definida de duas maneiras:- para identificação-própria um registro de Identificação taxonômica é criado na tabela de identifications e a coluna
identification_individual_idé preenchida com o próprioiddo indivíduo - para identificação-dependente, o id do Indivíduo que possui a Identificação é armazenado na coluna
identification_individual_id. - Conseqüentemente, o modelo Indivíduo contém dois métodos para se relacionar com o modelo de Identificação: um que define identificação-própria e outro que recupera as identificações taxonômicas usando a coluna
identification_individual_id.
- para identificação-própria um registro de Identificação taxonômica é criado na tabela de identifications e a coluna
- Os indivíduos podem ter um ou mais Vouchers depositados em uma BioColeção.
Acesso a dados Indivíduos pertencem a conjuntos de dados, então a política de acesso do conjuntos de dados se aplica aos indivíduos nele inseridos. Apenas os colaboradores e administradores do Conjunto de Dados podem inserir ou editar indivíduos, mesmo se o conjunto de dados for de acesso público.
Taxons
A ideia geral por trás do modelo Taxon é ferramentas para incorporar facilmente nomes taxonômicos válidos de repositórios Taxonômicos Online (atualmente Tropicos.org, GBIF e ZOOBANK estão implementados), mas permitindo a inclusão de nomes que também não são considerados válidos porque eles ainda são não publicados (por exemplo, um morfotipo), ou o usuário discorda da sinonímia publicada, ou o usuário deseja que todos os sinônimos sejam registrados como táxons inválidos no sistema. Além disso, permite definir um nível taxonômico de tipo
clado, permitindo armazenar, além das categorias de classificação taxonômica, qualquer nó da árvore da vida. Qualquer táxon registrado pode ser usado em identificações de Indivíduos e Medições podem ser vinculadas a nomes taxonômicos.
Tabela Taxon
- Como, Localidades, o modelo Taxon tem um relacionamento pai-filho, implementado usando o modelo de conjunto aninhado para dados hierárquicos da biblioteca Laravel Baum que permite consultar ancestrais e descendentes. Consequentemente, as colunas
rgt,lftedephda tabela de taxons são preenchidas automaticamente por esta biblioteca na inserção ou atualização dos dados. - Para ambos, Taxon
authore Taxonbibreference, existem duas opções:- Para nomes publicados, a autoria da string recuperada pelas APIs será colocada na coluna
author = string. Para nomes não publicados, o autor é uma pessoa e será armazenado na colunaauthor_id. - Somente nomes publicados podem ter relação com BibReferences. O campo de string
bibreferenceda tabela Taxon armazena as strings recuperadas por meio de APIs externas, enquanto obibreference_idse vincula a um objeto Referência Bibliográfica. Eles são usados para armazenar a publicação onde o nome do táxon é descrito e pode ser inserido em ambos os formatos. - Além disso, um registro de táxon também pode ter muitas outras referências de Bib por meio de uma tabela dinâmica (
taxons_bibreference), permitindo vincular qualquer número de referências bibliográficas a um nome de táxon.
- Para nomes publicados, a autoria da string recuperada pelas APIs será colocada na coluna
- A coluna
levelrepresenta a classificação taxonômica (como ordem, gênero, etc.). Ele é numericamente codificado e padronizado de acordo com as regras gerais do IAPT, mas deve acomodar também categorias de nível de táxon relacionadas a animais. Consulte os códigos disponíveis na API Taxon para obter a lista de códigos. - A coluna
parent_idindica o pai do táxon, que pode estar vários níveis acima dele. O nível dos pais deve ser estritamente mais alto do que o nível do táxon, mas você não precisa seguir a hierarquia completa. É possível registrar um táxon sem os pais, por exemplo, um morfotipo não publicado para o qual o gênero e a família são desconhecidos pode ter umaordemcomo pai. - Os nomes das classificações taxonômicas são traduzidos de acordo com o
localedefinido pelo sistema, que também traduz a interface da web (atualmente implementados apenas em português e inglês). - O campo
nomeda tabela de táxons contém apenas a parte específica do nome (no caso de espécies, o epíteto específico), mas a inserção e exibição dos táxons por meio da API ou interface web deve ser feito com a combinação fullname. - É possível incluir sinônimos na tabela Taxon. Para isso, deve-se preencher o relacionamento
senior, que é o id do nome aceito (valid) para um táxoninvalid. Sesenior_idfor preenchido, o táxon é um sinônimojuniore deve ser marcado como invalid. - Ao inserir um novo táxon publicado, apenas o
nomeé necessário. O nome será validado e o autor, referência e sinônimos serão recuperados usando os seguintes serviços de API:- BackBone Taxonômico do GBIF - esta será a primeira verificação, da qual links para Tropicos e IPNI também podem ser recuperados se registrar um nome de planta.
- Tropicos - se não for encontrado no GBIF, o ODB pesquisará o nome no banco de dados de nomenclatura do Jardim Botânico do Missouri.
- IPNI - o Índice Internacional de Nomes Individuais é outro banco de dados usado para validar nomes individuais (temporariamente desativado)
- MycoBank - usado para validar um nome se não for encontrado pelos Tropicos nem IPNI apis, e usado para validar nomes para Fungi. Temporariamente desativado
- ZOOBANK - quando GBIF, Tropicos, IPNI e MycoBank não conseguem encontrar um nome, então o nome é testado contra a api ZOOBANK, que valida os nomes dos animais. Não fornece publicação de táxons, no entanto.
- Se um nome de táxon for encontrado nos bancos de dados Nomenclatural, o respectivo ID do repositório é armazenado nas tabelas
taxon_external, criando um link entre o registro do táxon OpenDataBio e o banco de dados nomenclatural externo. - Pessoas pode ser definidas como especialistas em táxons por meio de uma tabela dinâmica. Assim, um objeto Taxon pode ter vários especialistas taxonômicos registrados no OpenDataBio.
Acesso a dados: usuários plenos podem registrar um novo táxon e editar os registros existentes se eles não tiverem sido usados para identificação. Atualmente é impossível remover um táxon do banco de dados. A lista de táxons tem acesso público.
Vouchers
O modelo Voucher é usado para armazenar registros de espécimes ou amostras de indivíduos depositados em BioColeções. Portanto, as únicas informações obrigatórias exigidas para registrar um Voucher são individual, biocollection e se o espécime é um tipo de nomenclatural (o padrão é non-type se não informado).
Vouchers table explained
- O Voucher pertence a um Indivíduo e a uma Biocoleção, portanto o
individual_ide obiocollection_idsão obrigatórios nesta tabela; biocollection_numberé o código alfanumérico do Voucher na Biocoleção, pode ser ’nulo’ para usuários que desejam apenas indicar que um Indivíduo registrado tem Vouchers em uma Bicoleção específica, ou para Vouchers registrados para biocoleções que não tem um código identificador;biocollection_type- é um código numérico que especifica se o Voucher na BioCollection é um tipo nomenclatural. O padrão é0(não é um tipo);1apenas para ‘Tipo’, uma forma genérica e outros números para outros tipos nomenclaturiscollectors, um ou múltiplos, são opcionais para Vouchers, exigidos apenas se forem diferentes dos Coletores do Indivíduo. Caso contrário, os coletores do Indivíduo são herdados pelo Voucher. Como para indivíduos, eles são implementados por meio de uma relações polimórfica com a tabela de collectors e o primeiro coletor é o coletor_principal para o voucher, ou seja, aquele que se relaciona comnumber.number, este é o número do coletor, mas como coletores, só deve ser preenchido se for diferente do valor datagdo indivíduo. Portanto,collectors,numberedatesão úteis para registrar Vouchers para Indivíduos que têm Vouchers coletados em momentos diferentes por pessoas diferentes.- O campo
datenos modelos indivíduos e Voucher pode ser uma data incompleta. Exigido apenas se for diferente do indivíduo a quem o voucher pertence. dataset_ido Voucher pertence a um Dataset, que controla a política de acesso;notesqualquer anotação de texto para o Voucher.- O modelo de Voucher interage com o modelo BibReference, permitindo vincular citações múltiplas a Vouchers. Isso é feito através da table
voucher_bibreference.
Acesso a dados Os vouchers pertencem a Conjuntos de Dados, portanto, a política de acesso a conjuntos de dados se aplica aos vouchers nele contidos. Os vouchers podem ter um conjunto de dados diferente de seus indivíduos. Se a política do conjunto de dados do Voucher for de acesso aberto e a Indivíduo não, o acesso aos dados do voucher será incompleto, portanto, o conjunto de dados do Voucher deve ter a mesma política de acesso ou uma política de acesso menos restrito do que o conjunto de dados do Indivíduo. Apenas os colaboradores e administradores do conjunto de dados podem inserir ou editar vouchers em um conjunto de dados, mesmo se o conjunto de dados for de acesso público.
Arquivos de Mídia
Arquivos de mídia (imagens, vídeos, áudios) são objetos centrais e podem receber Medições, além de descrições, tags e links para Localidades, Indivíduos, Vouchers ou Taxons.
- Relacionamento principal: polimórfico (
model_type,model_id) para Individual, Voucher, Localidade, Táxon ou Projeto. - dataset_id opcional: quando presente, a licença e o acesso herdam do Dataset; quando ausente, a mídia pode usar apenas
project_idou ficar solta (ainda com controles básicos). - project_id opcional: útil para agrupar e controlar acesso de mídia mesmo sem dataset.
- Coletores: créditos via tabela polimórfica collectors (múltiplas Pessoas).
- Tags: muitas-para-muitas com Tags, facilitando filtros.
- Custom properties (Spatie Media Library):
license(fallback se não houver dataset),date(usada em citações),notes,user_id,voucher_idelocation_idauxiliares,citation_fields(define o que entra na citação), além deuuide URLs gerados pela biblioteca. - Citações: geradas automaticamente a partir de autores, táxon, dataset/projeto, localização, licença e uuid; BibTeX disponível (
generate_citation). - Armazenamento: usa o pacote spatie/laravel-medialibrary; arquivos ficam no disco configurado e metadados na tabela
media. - Upload: interface web aceita lote (zip + csv) e metadados; API
mediasegue a mesma lógica. - Medições: aceitam medições via relação polimórfica.
Acesso a dados: se houver dataset_id, a política/licença seguem o Dataset; caso contrário, valem as permissões do Projeto ou as regras gerais de mídia. Usuários completos podem registrar mídia; administradores do dataset (quando existir) também podem excluí-la.
4.2 - Objetos de Atributos
Medições
A tabela measurements armazena os valores para variáveis medidas para os objetos centrais, incluindo Arquivos de Mídia. Seu relacionamento com os objetos centrais é definido por uma relações polimórficas usando as colunas measured_id e measured_type.
- medições devem pertencer a um Conjuntos de dados - coluna
dataset_id, que controla a política de acesso - Uma Pessoa deve ser indicada como o medidor (
person_id); - A coluna
bibreference_idpode ser usada para vincular medições extraídas de publicações à sua fonte fonte Bibliográfica - O valor para a variável medida (
trait_id) será armazenado em colunas diferentes, dependendo do tipo de variável:value- esta coluna flutuante armazenará valores para características reais quantitativas;value_i- esta coluna inteira armazenará valores para características Quantitative Integer; e é um campo opcional para características do tipo Link, permitindo, por exemplo, armazenar contagens para uma espécie (uma característica Link Taxon) em um local.value_a- esta coluna de texto armazenará valores para os tipos de traço Texto, Cor e Espectral.
- Valores para variáveis categóricas e ordinais são armazenados na tabela
measurement_category data- a data de medição é obrigatória em todos os casos
Acesso a dados As medições pertencem a Conjuntos de dados, portanto, a política de acesso a conjuntos de dados se aplica às medições nele. Apenas os colaboradores e administradores do conjunto de dados podem inserir ou editar medições em um conjunto de dados, mesmo se o conjunto de dados for de acesso público.
Variáveis
A tabela traits representa as variáveis definidas pelo usuário para coletar Mediçõespara um dos objetos centrais.
Essas características personalizadas fornecem enorme flexibilidade aos usuários para registrar suas variáveis de interesse. Obviamente, tal flexibilidade tem um custo na padronização dos dados, pois uma mesma variável pode ser registrada de forma diferentes em qualquer instalação do OpenDataBio. Para minimizar a redundância na ontologia de características, os usuários que criam características são avisados sobre esse problema e uma lista de características semelhantes é apresentada no caso de ser encontrada por comparação de nomes de características.
As variáveis têm restrições de edição para evitar perda de dados ou alteração não intencional do significado dos dados. Portanto, embora a lista de variáveis esteja disponível para todos os usuários, as definições de variáveis não podem ser alteradas se outra pessoa também usou a variável para armazenar medições.
Variáveis são entidades traduzíveis, então seus valores de name e description podem ser armazenados em vários idiomas (veja traduções de usuário. Isso é colocado na tabela user_translations através de uma relação polimórfica.
A definição da variável deve ser tão específica quanto necessário. A medição da altura das árvores usando medição direta ou um clinômetro, por exemplo, pode não ser facilmente convertida de uma para outra e deve ser armazenada em variáveis diferentes. Portanto, é altamente recomendável que o campo de definição de variável inclua informações como instrumento de medição e outros metadados que permitam que outros usuários entendam se podem usar sua variável ou criar uma nova.
- A definição da variável deve incluir um
export_name, que será usado durante as exportações de dados nos formulários de entrada da interface. Os nomes de exportação devem ser únicos e não devem ter tradução. São recomendados nomes de exportação curtos e [camelCase](https://en.wikipedia.org/wiki/Camel_case) ou [PascalCase](https://en.wikipedia.org/wiki/pascal_case). - Os seguintes tipos de características estão disponíveis:
- Quantitativo real - para números reais;
- Número inteiro quantitativo - para contagens;
- Categórico - para varáveis categóricas de seleção única;
- Múltiplo categórico - para muitas categorias selecionáveis;
- Ordinal categórico - para uma categoria ordenada selecionável (dados semiquantitativos);
- Texto - para qualquer valor de texto;
- Cor - para qualquer valor de cor, especificado pelo código de cor hexadecimal (paleta de cores)
- Link - este é um tipo de variável especial no OpenDataBio. Apenas links para Taxons e Vouchers estão implementados. Exemplo de uso: se você deseja armazenar contagens de espécies conduzidas em uma Localidade, você pode criar uma variável do tipo de link_taxon ou link_voucher. A medição para tal variável terá um campo opcional
valuepara armazenar as contagens. Este tipo de característica também pode ser usado para especificar o hospedeiro de um parasita ou o número de insetos predadores. - Espectral - projetado para acomodar dados espectrais, compostos de vários valores de absorbância ou refletância para diferentes números de onda.
- GenBank - armazena os números de acesso do GenBank que permitem recuperar dados moleculares vinculados a indivíduos ou vouchers armazenados no banco de dados através do GenBank Serviço API.
- A tabela Traits contém campos que permitem a validação do valor da medição, dependendo do tipo de variável:
range_maxerange_min- se definido para variáveis quantitativas, as medições terão que se ajustar ao intervalo especificado;value_length- obrigatório apenas para variáveis espectrais, valida o comprimento (número de valores) de uma medição espectral;link_type- se a variável for do tipo Link, a medição emvalue_ideve ser um id do objeto do tipo de link;- Para variáveis do tipo cor, os valores são validados no processo de criação da medição e devem estar em conformidade com um código hexadecimal de cores. Um seletor de cores é apresentado na interface web para inserção e edição de medições de cores;
- Variáveis categóricas e ordinais serão validadas para as categorias registradas ao importar medições por meio da API;
- A coluna
unitdefine a unidade de medida para a variável. - A coluna
bibreference_idé a chave de uma única Referência Bibliográfica que pode ser vinculad à definição da variável. - A tabela
trait_objectsarmazena o tipo de objetos centrais para o qual a variável pode ter uma medição;
Acesso aos dados O nome, definição, unidade e categorias de uma variável não podem ser atualizados ou removidos se houver alguma medição registrada no banco de dados. As únicas exceções são: (a) é permitido adicionar novas categorias para variáveis categóricas (não ordinais); (b) o usuário atualizando a variavel é a única pessoa que possui medições para a característica; (c) o usuário que atualiza a variável é um administrador de todos os conjuntos de dados com medições usando a variável.
Formulários (web e coleta móvel)
A table formulários armazena formulários do usuário de dois tipos:
- Formulários para uso na interface web:
- este formulário simplesmente agrega variáveis para capturar medições simultaneamente.
- você pode usar esse tipo de formulário para agregar medições a um determinado objeto central, individualmente
- ou criar uma Tarefa de preenchimento - FormTask, através da interface web, que serve para coletar um conjunto de variáveis para um conjunto de objetos de forma sequencial, garantindo que dados são coletados para todos os objetos alvo; pode definir que usuários tem permissão para incluir dados em uma tarefa
- Formulários para uso pelo aplicativo Opendatabio ODBCollect
- esse tipo de formulário visa facilitar a coleta de dados atravé de dispositivos Android
- você define o tipo de formulário segundo o tipo de informação que deseja coletar, define várias opções do que irá coletar, pode incluir bibliotecas de nomes taxonômicos, captura de imagens e geolocalização, e onde os dados devem ser salvos;
- define também quem pode usar o formulário
- coleta os dados offline usando o ODBCollect e quando houver conexão o usuário envia os registros coletados que são armazenados no servidor
As definições do usuário para os formulários são salvas no attributo definition da tablea forms. O job odbCollectPrepare é executado quando a definição é alterada para os formulários de tipo ODBCollect, e através desse job as bibliotecas indicadas nas definições (taxons, registros a serem medidos) são geradas e o formulário fica habilitado para ser usado.
A API importOdbCollect recebe os dados enviados pelo usuário e armazena no banco de dados conforme o tipo de formulário e dado informado e uma resposta é enviada ao ODBCollect indicando o status do registro.
4.3 - Objetos de Acesso
Os objetos centrais são: Localidades, Vouchers, Individual, Taxons e Arquivos de Mídia. Essas entidades são consideradas “centrais” porque podem receber Medições, ou seja, você pode registrar valores para qualquer Variável.
Conjuntos de dados controlam acesso aos dados e representam um publicação de dados dinâmica, cuja versão é definida pela data da última edição do registros incluídos. Conjuntos de dados contém Medições, Indivíduos, Vouchers e Arquivos de Mídia.
Projetos são apenas grupos de Conjuntos de dados e de Usuários, representando grupos de usuários com acessibilidade comum a conjuntos de dados cuja privacidade é definida para ser controlada por um projeto.
BioColeções - este modelo serve para criar uma lista reutilizável de acrônimos de Coleções Biológicas no registro de Vouchers. Mas tem opcionalmente a possibilidade de gerir uma coleção de registros de Vouchers e seus Indivíduos, paralelamente ao controle provido por Conjuntos de dados. O controle é apenas na edição e na entrada de dados. Neste caso a BioColeção é administrada pelo sistema.
Projetos e BioColeções devem ter pelo menos um Usuário definido como administrador, que tem controle total sobre o conjunto de dados ou projeto, incluindo a atribuição das seguintes funções a outros usuários: administrador, colaborador ouvisualizador:
- Colaboradores podem inserir e editar objetos, mas não podem excluir registros, nem alterar o conjunto de dados ou a configuração do projeto.
- Visualizadores têm acesso somente de leitura aos dados que não são de acesso aberto.
- Apenas usuários plenos e super-admins podem ser designados como administradores ou colaboradores. Assim, se um usuário que era administrador ou colaborador de um conjunto de dados for rebaixado a “Usuário registrado”, ele se tornará um visualizador.
- Super-admins apenas podem habilitar uma BioColeção para ser administrada pelo sistema.
BioColeções
O modelo Biocollection tem duas funções: (1) prover uma lista de acrônimos para registrar Vouchers de qualquer Coleção Biológica ; (2) gerir os dados de uma Coleção Biológica, facilitando o registro de novos dados (qualquer usuário entra seus dados usando as validações realizadas pelo software e solicita pela interface aos curadores da Coleção o registro dos dados que é feito pelos usuários autorizados na BioColeção, que a partir da transferência passa a controlar a edição dos dados dos Indivíduos. A opção (2) precisa ser implementada por um usuário SuperAdministrador do sistema, que ao habilitar a BioColeção para ser administrada pelo sistema, implementa o modelo de solicitações ODBRequest para que usuários possam pedir dados, amostras, ou registros e mudanças nos dados.
O objeto Biocollection pode ser uma Coleção Biológica formal, como as registradas no Index Herbariorum, ou qualquer outra Coleção Biológica.
O objeto Biocollection também interage com o modelo Person. Quando uma Pessoa está vinculada a uma Biocoleção, ela será listada como especialista taxonômico e pode ter também um vínculo com Taxons.
Acesso a dados - Usuários plenos podem registrar BioColeções, mas apenas usuários super-administradores podem tornar uma BioColeção adminstrável pelo sistema. Remover BioColeções pode ser feito se não há Vouchers ligados e se não é administrada pelo sistema. Se administrável, o modelo interage com Usuários, que podem ser administradores (curadores, pode tudo) ou colaboradores (podem entrar e editar dados, mas não podem apagar registros). Dados de outros Conjuntos de Dados podem fazer parte da BioColeção, permitindo que usuários tenham seus dados completo, mas o controle da edição dos registros é da BioColeção.
Conjuntos de Dados
Conjuntos de Dados são grupos de Medições, Indivíduos, Vouchers Arquivos de Mídia, e podem ter um ou mais Usuários administrators, collaborators ou viewers.
Administradores podem definir o nível de acesso para:
- acesso público
- restrito à usuários cadastrados
- restrito à usuários autorizados
- restrito à usuários do projeto.
Conjuntos de dados podem ter muitas Referências bibliográficas, que junto com os campos policy, metadata permitem anotar o conjunto de dados com informações relevantes para o compartilhamento de dados:
* Vincule qualquer publicação que tenha usado o conjunto de dados e, opcionalmente, indique se são de citação obrigatória ao usar os dados;
* Defina uma política de dados específica ao usar os dados além de uma licença pública [CreativeCommons.org]((https://creativecommons.org/licenses/)
* Detalhe quaisquer metadados relevantes, além daqueles que são automaticamente recuperados do banco de dados, como as definições das Variáveis medidas.
Versionamento de Conjuntos de Dados
Você pode gerar uma ou mais versões estáticas (dataset_versions) para cada conjunto de dados. Quando fizer isso serão gerados arquivos em csv com todos os dados e metadados para distribuição e acesso rápido. O versionamento inclui:
version- versionamento semântico para o conjunto de dadosdate- a data da versãolicense/license_version- a licença pública [CreativeCommons.org]((https://creativecommons.org/licenses/)policy(opcional) - um markdown para você definir a política de uso dos dadoscitation- você define o que seja incluir na citação para a versão e o Opendatabio gera a citação e fornece um bibtex para elametadata(opcional) - um espaço para você falar dos metadados primáriosfilters(opcional) - filtros permitem gerar versões para uma parte dos dados num conjunto de dados (por táxons, localidades, pessoas, traits, datas), registrando exatamente o escopo dos arquivos gerados.- As versões mantêm a lista de autores (pivô
dataset_version_person) do conjunto de dados - Um identificador único
UUIDé gerado para cada versão - Os arquivos gerados são armazenados e referenciados em
metadata['files']emetadata['archives']com o UUID. - O nível de acesso da versão (
dataset_access) pode ser igual ou menos restritivo que o do conjunto de dados, mas o principal objetivo é que versões tenha acesso público. - Downloads são auditados, mantendo um log do uso e do acesso;
- A API
datasetsexpõe as versões para listagem e download; a interface web usa um componente Livewire para criar/editar versões com pré-visualização da política e citação.
Projetos
Projetos são apenas grupos de Conjuntos de dados e interagem com Usuários, tendo administradores,colaboradores ou visualizadores. Esses usuários podem controlar todos os conjuntos de dados dentro do Projeto que tenham como política de acesso restrita aos usuários do projeto.
Usuários
O tabela users armazena informações sobre os usuários e administradores do banco de dados. Cada Usuário pode ser associado a uma Pessoa. Quando esse usuário insere novos dados, essa pessoa é usada como a pessoa padrão nos formulários. A pessoa só pode estar associada a um único usuário.
Existem três níveis de acesso possíveis para um usuário:
* Usuário registrado (o nível mais baixo) - tem muito poucas permissões
* Usuário pleno ou completo - podem ser atribuídos como administradores ou colaboradores de Projetos e Conjuntos de Dados;
* SuperAdmin (o nível mais alto). - os superadministradores têm acesso a todos os objetos, independentemente da configuração do conjunto de dados. Categoria para os administradores da instalação.
Cada usuário é atribuído ao nível usuário registrado ao se auto-cadastrar numa instalação do OpenDataBio. Depois disso, alguém que seja SuperAdmin pode promovê-lo a Usuário Pleno ou SuperAdmin. SuperAdmins também podem definir se um usuário pleno tem permissão para promover usuários registrados para usuário pleno. Apenas superAdmins podem remover usuários do banco de dados.
Se o adminstrador do sistema configurar a opção EMAIL_VERIFICATION_ENABLED = true nas configurações do Opendatabio, usuários registrados receberão um link via email para validar o email registrado.
Acesso a dados: os usuários são criados no momento do registro e o acesso aos dados são restritos ao próprio usuário e aos administradores. Usuários registrados autorizados tem acesso apenas ao nome.
4.4 - Objetos Auxiliares
Referências Bibliográficas
A tabela bib_references contém basicamente referências formatadas em BibTex armazenadas na coluna bibtex. Você pode facilmente importar referências para o OpenDataBio através da interface, apenas especificando o doi ou simplesmente enviando um registro bibtex ou um arquivo .bib. Essas referências bibliográficas podem ser usadas para:
- Conjuntos de dados - com a opção de definir referências para as quais a citação é obrigatória quando o Conjunto de Dados for usado em publicações; mas todas as referências que usaram o conjunto de dados podem ser vinculadas ao conjunto de dados; os links são feitos com uma tabela dinâmica chamada
dataset_bibreference; - Taxons:
- para especificar a referência na qual o nome do táxon foi descrito, atualmente obrigatório em algumas revistas taxonômicas como PhytoTaxa. Esta referência de descrição é armazenada no
bibreference_idda tabela Taxons. - para registrar qualquer referência a um nome de táxon, que são então vinculados por meio de uma tabela dinâmica chamada
taxons_bibreference.
- para especificar a referência na qual o nome do táxon foi descrito, atualmente obrigatório em algumas revistas taxonômicas como PhytoTaxa. Esta referência de descrição é armazenada no
- Vincule uma Medição a uma fonte publicada;
- Indique a origem de uma definição de Variável.
- Indique citações obrigatórias para um conjunto de dados ou vincule referências usando os dados para um conjunto de dados
Tabela Bibreferences
- A
bibtexKey, autores e outros campos relevantes são extraídos do registro em formato bibtex armazenado na colunabibtex. - A ** bibtexkey deve ser única** no banco de dados e uma função auxiliar é fornecida para padronizá-la com o formato
<von? sobrenome> <ano> <primeira palavra do título>. A “parte von” do nome é “von”, “di”, “de la”, que fazem parte do sobrenome de alguns autores. A primeira palavra do título ignora palavras de interrupção comuns, como “a”, “o” ou “em”. - DOI para uma referencia pode ser especificado no campo BibTex relevante ou em uma entrada de texto separada, e são armazenados no campo
doiquando presente. Uma API externa encontra o registro bibliográfico quando um usuário informa odoina interface.
Acesso a dados usuários plenos podem registrar novas referências, editar detalhes de referências e remover registros de referência que não têm dados associados. BibReferences tem acesso público!
Identificação Taxonômica
O modelo Identificação representa a identificação taxonômica de Indivíduos.
Tabela identifications
- O modelo de Identificação inclui vários campos opcionais, mas além de
taxon_id, os identificadores (ligados via pivôidentification_person) e adatede identificação são obrigatórios.
- O valor de
datepode ser uma Data Incompleta, por exemplo apenas o ano ou ano + mês podem ser registrados.
- Os seguintes campos são opcionais:
modifier- é um código numérico que anexa um modificador taxonômico ao nome. Valores possíveis ’s.s.’ = 1, ’s.l.’ = 2, ‘cf.’ = 3, ‘aff.’ = 4, ‘vel aff.’ = 5, o padrão é 0 (nenhum).notes- um texto de escolha, útil para adicionar comentários à identificação.biocollection_idebiocollection_reference- esses campos devem ser usados para indicar que a identificação é baseada na comparação com um voucher depositado em uma coleção biológica e cria um link entre o indivíduo identificado e o espécime da BioColeção no qual a identificação foi baseada.biocollection_idarmazena o id de BioColeção ebiocollection_referenceo identificador único do espécime comparado, ou seja, seria o equivalente aobiocollection_numberdo modelo Voucher, mas esta referência não precisa ser de um voucher registrado no banco de dados.
- Cada identificação referencia diretamente
individual_id; não há mais relacionamentos polimórficos para identificações. - Mudanças na Identificação de Indivíduos são auditadas para rastrear o histórico de mudanças
Acesso aos dados: as identificações são atributos dos Indivíduos e não possuem acesso independente!
Pessoas
O modelo Persons armazena nomes de pessoas que podem ou não ser um Usuário diretamente envolvido com a base de dados. Pessoas podem ser:
* coletores de Vouchers, Indivíduos e Arquivos de Mídia
* identificadores taxonômicos de Indivíduos;
* medidores de Medições;
* autores para nomes não publicados de Taxons;
* especialistas taxonômicos - ligados ao modelo Taxon pela tabela person_taxon;
* autores de Conjuntos de Dados
Tabela persons
- as colunas obrigatórias são a pessoa
full_nameeabbreviation; - ao cadastrar uma nova pessoa, o sistema sugere o nome
abbreviation, mas o usuário é livre para alterá-lo para melhor adaptá-lo à abreviatura usual de cada pessoa. A ** abreviatura deve ser única ** no banco de dados, duplicatas não são permitidas na tabela Pessoas. Portanto, duas pessoas com exatamente o mesmo nome devem ser diferenciadas de alguma forma na colunaabbreviation. - A coluna
biocollection_idda tabela Pessoas é usada para listar a qual BioColeção uma pessoa está associada, que pode ser usada quando a Pessoa também é um especialista taxonômico. - Adicionalmente, também podem ser informados o
e-maile ainstitutiona que pertence a pessoa. - Cada usuário pode ser vinculado a uma pessoa pelo
person_idna tabela Usuário. Essa pessoa é então usada como a pessoa ‘padrão’ quando o usuário está logado no sistema.
Acesso a dados usuários plenos podem registrar novas pessoas e editar as pessoas inseridas e remover pessoas que não possuem dados associados. Os administradores podem editar qualquer pessoa. A lista de pessoas tem acesso público.
Tag Model
O modelo Tag permite que os usuários definam palavras-chave traduzíveis que podem ser usadas para sinalizar Conjuntos de dados, Projetos ou Arquivos de Mídia. O modelo Tag está vinculado a esses objetos por meio de uma tabela para cada um, denominada dataset_tag, project_tag e media_tag, respectivamente.
Um Tag pode ter name e description em cada idioma configurado na tabela de Idiomas, que serão armazenados na tabela user_translations. As entradas para cada idioma são mostradas nos formulários da interface.
Acesso a dados usuários plenos podem registrar tags, editar as inseridas e excluir as que não foram usadas. As tags têm acesso público, pois são apenas palavras-chave para facilitar a navegação.
Jobs do usuário
A tabela user_jobs é usada para armazenar temporariamente tarefas que são executadas em segundo plano, como a importação e exportação de dados. Qualquer usuário tem permissão para criar um Job; cancelar seus próprios Jobs; listar os Jobs que não foram excluídos.
A tabela jobs contém os dados usados pelo framework Laravel para interagir com a Queue. Os dados desta tabela são excluídos quando o trabalho é executado com êxito. A tabela user_jobs é usada para manter essas informações, além de permitir logs do processo, repetir tarefas com erros e cancelar tarefas que ainda não foram concluídas.
Jobs com mais de 30 dias podem ser removidos automaticamente para todos os usuários através do comando CleanOldUserJobs, que o administrador pode rodar manualmente ou colocar num cron job para rodar com certa frequência automaticamente.
Acesso a dados: Cada usuário registrado pode ver, editar e remover seus próprios Jobs.
Traduções do usuário
O modelo UserTranslation armazena as traduções de dados do usuário para: descrições e nomes de Variáveis e de categorias para variáveis categóricas; descrições de Arquivos de Mídia e para Tags. As relações com esses modelos são estabelecidas por relações polimórfica usando os campos translatable_type e translatable_id. Este modelo permite traduções para qualquer idioma listado na tabela languages, atualmente acessível apenas para inserção e edição diretamente no banco de dados SQL. Os formulários de entrada na interface web serão listados para os idiomas registrados.
Vernacular - Nome Popular
Os modelos Vernacular e VernacularCitation permitem registrar nomes populares de organismos, relacionando-os à Taxons e/ou Individuals, ou de paisagens e tipos de ambiente e vegetação, relacionando-os à Locations. A combinação nome+idioma deve ser única na tabela vernaculars e cada registro pode ser vinculado a múltiplos Táxons e/ou Indivíduos, ou Localidades, dependendo das fontes de informação. Cada registro também pode ter uma ou mais citações (texto de citação + BibReference + nota).
- Suporta múltiplos idiomas para o nome popular; o idioma é obrigatório em cada registro e a interface já tem cadastrada uma lista ampla de valores possíveis em
config/languagesISO6393.php - VernacularCitations permite adicionar várias citações sobre os nomes populares.
- Formulários ODBCollect podem exigir nomes populares, permitindo capturar o vernacular no campo junto com medições, táxon e/ou indivíduo, e/ou com uma localidade.
Formulários
Consulte a seção de Formulários em Objetos de Atributos, que detalha o uso na interface web e no aplicativo OpenDataBio Collect.
Datas incompletas
Datas para Vouchers, Indivíduos, Medições e Identificações podem ser incompletas, mas pelo menos ano é obrigatório em todos os casos. As colunas date nas tabelas são do tipo ‘date’ e as datas incompletas são armazenadas com 00 na parte ausente: ‘2005-00-00’ quando apenas o ano é conhecido; ‘1988-08-00’ quando apenas o mês é conhecido.
Auditando mudanças
As modificações nos registros do banco de dados são registradas na tabela activity_log. Esta tabela é gerada pelo pacote ActivityLog. As atividades são mostradas em um link ‘Histórico’ fornecido no show.view dos modelos.
- O pacote armazena as alterações como json no campo
properties, que contém dois elementos:attributeeold, que são basicamente os valores novos vs antigos que foram alterados. Essa estrutura deve ser respeitada. - A classe ActivityFunctions contém funções personalizadas para ler as propriedades do registro Json armazenado na tabela
activity_loge encontra os valores para mostrar na tabela de dados History; - A maioria das mudanças são registradas pelo pacote como um ’trait’ chamada dentro da classe. Estes permitem registrar automaticamente a maioria das atualizações e são configurados para registrar apenas os campos que foram alterados, não registros inteiros (opção
dirty). Além disso, a criação de registros não é anotada como atividade, apenas as alterações. - Algumas alterações, como de coletores e de identificações indivíduos são registradas separadamente, pois envolvem tabelas relacionadas e o registro é especificado nos arquivos do Controlador;
- O registro contém um campo
log_nameque agrupa os tipos de registro e é usado para distinguir os tipos de atividade e é útil para pesquisar a tabela de dados do histórico; - Dois registros especiais também são feitos para Conjuntos de Dados:
- Qualquer download de um Conjunto de Dados pela interface é registrado, então os administradores podem rastrear quem e quando o conjunto de dados foi baixado;
- Qualquer solicitação de conjunto de dados também é registrada pelo mesmo motivo
O clean-command do pacote NÃO DEVE ser usado durante uma instalação em produção, caso contrário, apagará todas as alterações registradas. Se executado, apagará os logs anteriores ao tempo especificado no arquivo /config/activitylog.php.
A tabela ActivityLog tem a seguinte estrutura:
{
"attributes":
{
"person_id":"2",
"taxon_id":"1424",
"modifier":"2",
"biocollection_id":"1",
"biocollection_reference":"1234",
"notes":"A new fake note has been inserted",
"date":"2020-02-08"},
"old":{
"person_id":674,
"taxon_id":1413,
"date":"1995-00-00",
"modifier":0,
"biocollection_id":null,
"notes":null,
"biocollection_reference":null
}
}
5 - Como contribuir
Reportar bugs e sugerir melhorias
Criar um issue em um dos repositórios GitLab abaixo, dependendo do problema.
Antes de postar, verifique se o que você quer relatar, perguntar ou propor já não está num issue aberto.
Identifique seu problema com uma ou mais etiquetas.
Issues para software
Issues para o pacote do R
Issues para este site de documentação
Colabore com o desenvolvimento, traduções de idiomas e documentos
Esperamos que este projeto cresça de forma colaborativa, necessário para o seu desenvolvimento e utilização no longo prazo. Portanto, colaboradores são bem-vindos para ajudar a corrigir e melhorar o OpenDataBio. A lista de problemas ou melhorias é um lugar para começar a saber o que é necessário fazer. Você pode também contribuir com Tutorias, melhorando a documentação.
As seguintes diretrizes são recomendadas se você deseja colaborar:
- Comunique-se com o administrador do repositório OpenDataBio indicando em quais questões deseja trabalhar e junte-se à equipe de desenvolvimento.
- Faça um
Forkdo repositório - Boa prática criar um
branchpara guardar suas modificações ou adições - Quando estiver satisfeito com os resultados, faça uma solicitação de
pull-requestao mantenedor do projeto para revisar sua contribuição e mesclá-la com o código do repositório. Consulte a Ajuda do GitLab para obter mais informações sobre pull requests.
Diretivas de programação
- Use a instalação do docker para desenvolvimento, compartilhada entre os desenvolvedores. A interface agora usa Livewire 3 + Alpine para formulários e tabelas; novos CRUDs e filtros devem seguir esse padrão.
- Este software deve aderir ao Controle de Versão Semântico, a partir da versão 0.1.0-alpha1. O pacote R complementar e a Documentação (este site) devem seguir um esquema de controle de versão semelhante. Ao alterar a versão, uma tag de lançamento (release) deve ser criada com a versão antiga.
- Todas as variáveis e funções devem ser nomeadas em Inglês, com as entidades e campos relacionados ao banco de dados sendo nomeados no singular. Todas as tabelas (quando apropriado) devem ter uma coluna “id” e as chaves estrangeiras devem fazer referência à tabela base com o sufixo “_id”, exceto em casos de autojunções (como “taxon.parent_id”) ou chaves estrangeiras polimórficas. O id de cada tabela tem tipo INT e deve ser autoincrementado.
- Use a classe laravel migration para adicionar qualquer modificação à estrutura do banco de dados. A migração deve incluir, se aplicável, a manipulação de dados existentes, permitindo upgrades.
- Use camelCase para métodos (ou seja, relacionamentos) e snake_case para funções.
- Documente o código com comentários e crie páginas de documentação neste site, se necessário.
- Deve haver uma estrutura para armazenar quais plugins estão instalados em uma determinada versão do banco de dados quais são as versões de sistema compatíveis.
- Este sistema usa Vite para compilar o código SASS e JavaScript. Se você adicionar ou modificar esses arquivos, utilize
npm run build(ounpm run devdurante o desenvolvimento).
Colabore com a documentação
Tutoriais para lidar com tarefas específicas são bem vindos!
Para criar um tutorial:
Forko repositório de documentação. Ao clonar este repositório ou do seu fork inclua a opção de submódulo para obter também o repositório de tema Docsy incluído. Você precisará de Hugo para executar este site em seu localhost.- Crie um
branchpara confirmar suas modificações ou adições - Adicione seu tutorial:
- Crie uma pasta dentro de
contents/{lang}/docs/Tutorialsusando kebab-case para o nome da pasta. Ex.primeiro-tutorial - Você pode criar um tutorial em um único idioma ou em vários idiomas. Basta colocá-lo na pasta correta
- Dentro da pasta criada, crie um arquivo chamado
_index.mde crie o conteúdo de markdown com seu tutorial. - Você pode começar copiando o conteúdo de um tutorial já incluído ou veja a documentação do Docsy
- Quando estiver satisfeito com os resultados, faça uma solicitação de pull para pedir ao mantenedor do projeto para revisar sua contribuição e mesclá-la com o repositório. Consulte a Ajuda do GitLab para obter mais informações sobre o uso de solicitações pull.
Colabore com traduções
Você pode ajudar com as traduções da interface do aplicativo ou deste site com a documentação. Se quiser ter um novo idioma para sua instalação, compartilhe sua tradução, criando um pull request com os novos arquivos.
Novo idioma para a interface da web:
- faça um fork e crie um branch para o repositório principal
- crie uma pasta para o novo idioma usando o Código ISO 639-1 dentro da pasta
resources/lang
cd opendatabio
cd resources/lang
cp en es
- traduza todos os valores para todas as variáveis dentro de todos os arquivos na nova pasta (pode usar a tradução do google para começar, apenas certifique-se de que os nomes das variáveis não sejam traduzidos, caso contrário, não funcionará).
- adicione o idioma ao array em
config/languages.php - adicionar o idioma à tabela de languages do banco de dados criando uma migração laravel
- solicite um pull request
Novo idioma para o site de documentação
- faça um fork e crie um branch para o repositório de documentação
- crie uma pasta para o novo idioma usando o Código ISO 639-1 dentro da pasta
content
bash
cd opendatabio.gitlab.io
cd content
cp pt es
- verifique todos os arquivos dentro da pasta e traduza onde necessário (pode usar a tradução do google, apenas certifique-se de traduzir apenas o que pode ser traduzido)
- Veja se funciona bem na sua máquina local (precisa installar Hugo e servir digitando
hugo servena pasta do site, que ficará visível pelo navegador no endereço http://localhost:1313/. - empurre para o seu branch e faça um pull request
Relações polimóficas
Algumas das relações dentro da OpenDataBio são mapeadas usando Relações polimórficas. Elas são indicadas em um modelo por ter um campo terminando em _id e um campo terminando em _type. Por exemplo, todos os Objetos Centrais podem ter Medições, e essas relações são estabelecidas na tabela measurements pelas colunas measured_id e measured_type, o primeiro armazenando a id do modelo relacionado, o segundo é a classe do modelo medido em strings como ‘App\Models\Individual’, ‘App\Models\Voucher’, ‘App\Models\Taxon’, ‘App\Models\Location’.
Imagens do modelo conceitual
A maioria das figuras para explicar o modelo de dados foram geradas usando Laravel ER Diagram Generator, que permite mostrar todos os métodos implementados em cada modelo e não apenas os links diretos da tabela:
Para gerar essas figuras, um comando personalizado php artisan foi gerado. Esse commando está definido no arquivo app/Console/Commands/GenerateOdbErds.php.
Para atualizar as figuras siga os seguintes passos:
- As figuras são configuradas no arquivo
config/erd-generator-odb.php. Existem muitas opções adicionais para personalizar as figuras alterando ou adicionando variáveis graphviz ao arquivoconfig/erd-generator-base.php. - O comando personalizado é
php artisan odb: erd {$ model}, onde model é a chave dos arrays emconfig / erd-generator-odb.php, ou a palavra" all “, para regenerar todas as figuras doc.`bash cd opendatabio fazer ssh php artisan odb: erd all` - As figuras serão salvas em
storage / app / public / dev-imgs - Copie as novas imagens para a pasta do site de documentação. Eles precisam ser colocados em
contents / {lang} / concepts / {subfolder}para todos os idiomas e nas respectivas subpastas.
6 - Tutoriais
Este espaço do site OpenDataBio é para estudos de caso de uso do OpenDataBio pela interface, mas principalmente usando o OpenDataBio R package. Como contribuir com um tutorial.
6.1 - Obter dados via R
O pacote Opendatabio-R foi criado para permitir aos usuários interagir com um servidor OpenDataBio, para obter (GET) dados, importar (POST) dados para a base de dados e atualizar dados (PUT). Este tutorial é um exemplo básico de como obter dados.
Configure a conexão
- Configure a conexão com o servidor OpenDataBio usando a função
odb_config()do pacote. Os parâmetros mais importantes para esta função sãobase_url, que deve apontar para a URL da API do seu servidor OpenDataBio etoken, que é o token de acesso usado para autenticar seu usuário. - O
tokensó é necessário para obter dados de conjuntos de dados que possuem uma das políticas de acesso restrito. Os dados dos conjuntos de dados de acesso público podem ser extraídos sem a especificação do token. - Seu token está disponível em seu perfil na interface web
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="O SEU TOKEN AQUI"
cfg = odb_config(base_url=base_url, token = token)
A configuração mais avançada envolve a definição de uma versão de API específica, um agente de usuário personalizado ou outros cabeçalhos HTTP, mas isso não é coberto aqui.
Teste sua conexão
A função odb_test() pode ser usada para verificar se a conexão foi bem sucedida e se
seu usuário foi identificado corretamente:
odb_test(cfg)
#will output
Host: https://opendb.inpa.gov.br/api/v0
Versions: server 0.9.1-alpha1 api v0
$message
[1] "Success!"
$user
[1] "admin@example.org"
Como alternativa, você pode especificar esses parâmetros como variáveis de sistema. Antes de iniciar o R, configure isso em seu shell (ou adicione ao final de seu arquivo .bashrc):
export ODB_TOKEN="YourToken"
export ODB_BASE_URL="https://opendb.inpa.gov.br/api"
export ODB_API_VERSION="v0"
Obter dados
Verifique a Referência rápida da API GET para obter uma lista completa de endpoints e parâmetros de solicitação. Veja também os parâmetros genéricos, em especial
save_jobque é importante para baixar grandes conjuntos de dados.
Para dados de acesso público o token é opcional. Abaixo alguns exemplos. Siga um raciocínio semelhante para usar os demais endpoints. Veja a ajuda do pacote R para todas as funções odb_get_{endpoint} disponíveis.
Obtendo nomes de táxons
Consulte GET API Taxon Endpoint para uma lista dos parâmetros de solicitação e uma lista de campos de resposta.
base_url="https://opendb.inpa.gov.br/api"
cfg = odb_config(base_url=base_url)
#get id for a taxon
mag.id = odb_get_taxons(params=list(name='Magnoliidae',fields='id,name'),odb_cfg = cfg)
#use this id to get all descendants of this taxon
odb_taxons = odb_get_taxons(params=list(root=mag.id$id,fields='id,scientificName,taxonRank,parent_id,parentName'),odb_cfg = cfg)
head(odb_taxons)
Algo como, dependo da sua base:
id scientificName taxonRank parent_id parentName
1 25 Magnoliidae Clado 20 Angiosperms
2 43 Canellales Ordem 25 Magnoliidae
3 62 Laurales Ordem 25 Magnoliidae
4 65 Magnoliales Ordem 25 Magnoliidae
5 74 Piperales Ordem 25 Magnoliidae
6 93 Chloranthales Ordem 25 Magnoliidae
Obtendo Localidades e geometrias
Consulte GET API Location Endpoint para os parâmetros de solicitação e uma lista de campos de resposta.
Obtenha alguns campos listando todas as Unidades de Conservação (adm_level=99) registradas no servidor:
base_url="https://opendb.inpa.gov.br/api"
cfg = odb_config(base_url=base_url)
odblocais = odb_get_locations(params = list(fields='id,name,parent_id,parentName',adm_level=99),odb_cfg = cfg)
head(odblocais)
Se o servidor usar os dados de seed fornecidos o resultado será:
id name
1 5628 Estação Ecológica Mico-Leão-Preto
2 5698 Área de Relevante Interesse Ecológico Ilha do Ameixal
3 5700 Área de Relevante Interesse Ecológico da Mata de Santa Genebra
4 5703 Área de Relevante Interesse Ecológico Buriti de Vassununga
5 5707 Reserva Extrativista do Mandira
6 5728 Floresta Nacional de Ipanema
parent_id parentName
1 6 São Paulo
2 6 São Paulo
3 6 São Paulo
4 6 São Paulo
5 6 São Paulo
6 6 São Paulo
Localidades como objetos espaciais em R
Para obter um objeto espacial em R, use o pacote sf. O exemplo abaixo plota um gráfico e seus subgráficos e também exporta as localizações como kml e shapefile.
library(sf)
library(opendatabio)
#download dados de uma parcela
cfg <- odb_config(base_url = "https://opendb.inpa.gov.br/api")
#daddos da parcela
parcela = odb_get_locations(params = list(fields='all',name='Parcela 25ha'), odb_cfg = cfg)
parcela$type = 'main plot'
#subparcelas
subplots = odb_get_locations(params = list(fields='all',location_root=parcela$id), odb_cfg = cfg)
subplots = subplots[subplots$adm_level==100 & subplots$id!=parcela$id,]
subplots$type = 'sub plot'
#convert footprintWKT para sf geometries
geoms <- st_as_sfc(parcela$footprintWKT, crs = 4326)
parcela_sf <- st_sf(parcela, geometry = geoms)
geoms <- st_as_sfc(subplots$footprintWKT, crs = 4326)
subplots_sf <- st_sf(subplots, geometry = geoms)
#imprime
png("plots_with_subplots.png", width = 15, height = 15,units='cm',res=300)
par(mar=c(2,2,3,2))
plot(st_geometry(subplots_sf),border='green',main = parcela$locationName)
plot(st_geometry(parcela_sf),border='red',add=T)
labs = gsub("Quadrat ","",subplots_sf$locationName)
text(
st_coordinates(st_centroid(subplots_sf)),
labels = labs,
cex = 0.2, col = "blue"
)
dev.off()
#salva como kml
locais = rbind(parcela_sf,subplots_sf)
locais$name <- locais$locationName
cols_to_include <- setdiff(names(locais), c("footprintWKT",'locationName'))
locais_kml <- locais[, c("name", cols_to_include[cols_to_include != "name"])]
st_write(locais_kml, "plots_and_subplots.kml", layer=parcela$locationName, driver = "KML", delete_dsn = TRUE)
#salva como shapefile
st_write(locais_kml, "plots_and_subplots.shp", layer=parcela$locationName, delete_layer = TRUE)
Figura gerada:

Validando coordendas geográficas
Ver POST Locations-Validation Endpoint para parametros e campos resposta.
#sua conexao
library(opendatabio)
base_url="http://localhost/opendatabio/api"
token ="o seu token aqui"
cfg = odb_config(base_url=base_url, token = token)
odb_test(cfg)
#dados fake
dados = data.frame(
latitude = sample(seq(-2,2,by=0.00001),10),
longitude = sample(seq(-60,-59,by=0.00001),10)
)
#envia para validar
jb = odb_validate_locations(dados,odb_cfg = cfg)
#monitora execução
odb_get_jobs(params=list(id=jb$id),odb_cfg = cfg)
#pega resultado
dadosValidados = odb_get_jobs(params=list(id=jb$id,get_file=T),odb_cfg = cfg)
head(dados)
latitude longitude
1 0.12975 -59.65745
2 1.77469 -59.77757
3 -0.89154 -59.80179
4 -1.25632 -59.87084
5 0.77085 -59.22740
6 -0.74237 -59.64591
head(dadosValidados)
latitude longitude withinLocationName withinLocationParent withinLocationCountry withinLocationHigherGeography withinLocationType
1 0.12975 -59.65745 Trombetas/Mapuera Brasil Brazil Brasil > Trombetas/Mapuera Território Indígena
2 0.12975 -59.65745 Bioma Amazônia Brasil Brazil Brasil > Bioma Amazônia Ambiental
3 0.12975 -59.65745 Amazonia World Amazonia Ambiental
4 0.12975 -59.65745 Urucará Amazonas Brazil Brasil > Amazonas > Urucará Município
5 1.77469 -59.77757 Jacamim Roraima Brazil Brasil > Roraima > Jacamim Território Indígena
6 1.77469 -59.77757 Bioma Amazônia Brasil Brazil Brasil > Bioma Amazônia Ambiental
withinLocationID withinLocationTypeAdmLevel searchObs
1 6393 98 NA
2 6583 97 NA
3 16597 97 NA
4 1570 8 NA
5 6121 98 NA
6 6583 97 NA
Obtendo dados de Individuos
Consulte GET API Individual Endpoint para as listas completas das opções de parâmetros de busca e dos campos de reposta.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="O SEU TOKEN AQUI"
#estabelece a configuração da conexao
cfg = odb_config(base_url=base_url, token = token)
#BAIXA DIRETAMENTE - se forem poucos dados que voce quer baixar
inds = odb_get_individuals(params=list(limit=100),odb_cfg=cfg)
#PREPARA ARQUIVO NO SERVIDOR - se tua busca implicar em muito registros
#baixando todos os registros aos quais voce tem acesso ou publicos
#salvando o processo, pois neste caso devem ser muitos
jobid = odb_get_individuals(params=list(save_job=T),odb_cfg=cfg)
#verificando o status do processo
odb_get_jobs(params=list(id=jobid$job_id),odb_cfg=cfg)
#qual terminr, pega os dados aqui (ou baixe o arquivo gerado pela interface web)
todos.inds = odb_get_jobs(params=list(id=jobid$job_id),odb_cfg=cfg)
#BUSCANDO DADOS ESPECIFICOS
#todos os individuos identificados como o taxon X
params = list(taxon = "Licaria cannela tenuicarpa")
licarias = odb_get_individuals(params=params,odb_cfg=cfg)
#todos os individuos identificados como o taxon X ou seus descendentes
params = list(taxon_root = "Licaria")
licarias = odb_get_individuals(params=params,odb_cfg=cfg)
#todos individuos do conjunto de dados X
params = list(dataset = "MyDataset name or id")
inds = odb_get_individuals(params=params,odb_cfg=cfg)
#ou use o save_job acima se forem muitos dados
#pode ver a lista dos conjuntos de dados existentes
datasets = odb_get_datasets(odb_cfg = cfg)
Obtendo dados de Vouchers
Consulte GET API Voucher Endpoint para as listas completas das opções de parâmetros de busca e dos campos de reposta.
Siga o exemplo de indivíduos acima, mas usando a função odb_get_vouchers.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="O SEU TOKEN AQUI"
#estabelece a configuração da conexao
cfg = odb_config(base_url=base_url, token = token)
#100 primeiros vouchers com registro numa biocoleção
vouchers = odb_get_vouchers(params=list(biocollection="INPA",limit=100),odb_cfg=cfg)
#vouchers na localidade x (id, ou nome, como registrado na base)
vouchers = odb_get_vouchers(params=list(location="Reserva Florestal Adolpho Ducke, Parcela PDBFF-100ha",limit=100),odb_cfg=cfg)
Obtendo Medições
Consulte GET API Measurement Endpoint para as listas completas das opções de parâmetros de busca e dos campos de reposta.
Use a função odb_get_measurements.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="O SEU TOKEN AQUI"
#estabelece a configuração da conexao
cfg = odb_config(base_url=base_url, token = token)
#100 primeiras medições do conjunto de dados X com id=10
medicoes = odb_get_measurements(params=list(dataset=10,limit=100),odb_cfg=cfg)
#100 primeiras medições do conjunto de dados X com id=10 para a variavel cujo export_name é treeDbh
medicoes = odb_get_measurements(params=list(trait="treeDbh",dataset=10,limit=100),odb_cfg=cfg)
#Medições do conjunto de dados X com id=10 para a variavel cujo export_name é treeDbh
#apenas para Lauraceae
medicoes = odb_get_measurements(params=list(trait="treeDbh",dataset=10,taxon_root="Lauraceae"),odb_cfg=cfg)
#ligando dados de individuos medicoes
louros = odb_get_individuals(params=list(dataset=10,taxon_root="Lauraceae"),odb_cfg=cfg)
filtro = grep("Individu",medicoes$measured_type) #opcional, depende do que esta em medicoes
g = match(medicoes$measured_id[filtro],louros$id)
medicoes$location = NA
medicoes$location[filtro] = louros$locationName[g]
Obtendo Mídia
Consulte GET API Media Endpoint para as listas completas das opções de parâmetros de busca e dos campos de reposta.
Use a função odb_get_media do pacote do R.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="O SEU TOKEN AQUI"
#estabelece a configuração da conexao
cfg = odb_config(base_url=base_url, token = token)
#os 50 primeiros arquivos de mídia de um conjunto de dados que tem imagens
imgs = odb_get_media(params=list(dataset=97,limit=50),odb_cfg=cfg)
#veja esses metadados
head(imgs)
#a partir desses metadados, baixa os arquivos de media
#cria uma função para isso:
getImagesByURL <- function(url,downloadFolder='img') {
dir.create(downloadFolder,showWarnings = F)
fn = strsplit(url,"\\/")[[1]]
fn = fn[length(fn)]
nname = paste(downloadFolder,fn,sep="/")
img = httr::GET(url=url)
writeBin(httr::content(img, "raw"), nname)
}
#usa a função para baixar as imagens numa pasta
sapply(imgs$file_url,getImagesByURL,downloadFolder='testeImgsFromOdb')
Obter Conjuntos de dados
Versões publicadas de conjuntos de dados, são arquivos já prontos no servidor para uso. Essas versões, se disponíveis, podem ter acesso aberto ou restrito.
6.2 - Importar dados via R
O pacote Opendatabio-R foi criado para permitir aos usuários interagir com um servidor OpenDataBio, tanto para obter (GET) dados ou para importar (POST) dados para o banco de dados. Este tutorial é um exemplo básico de como importar dados.
Configure a conexão
- Configure a conexão com o servidor OpenDataBio usando a função
odb_config()do pacote. Os parâmetros mais importantes para esta função sãobase_url, que deve apontar para a URL da API do seu servidor OpenDataBio etoken, que é o token de acesso usado para autenticar seu usuário. - O
tokensó é necessário para obter dados de conjuntos de dados que possuem uma das políticas de acesso restrito. Os dados dos conjuntos de dados de acesso público podem ser extraídos sem a especificação do token. - Seu token está disponível em seu perfil na interface web
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
#create a config object
cfg = odb_config(base_url=base_url, token = token)
#test connection
odb_test(cfg)
Importar Dados (POST API)
Verifique a [Referência rápida da API]/docs/api/quick-reference) para obter uma lista completa dos POST endpoints e os campos necessários para importação de dados.
Funções de importação OpenDataBio-R
Todas as funções de importação têm a mesma assinatura: o primeiro argumento é um data.frame com os dados a serem importados, e o segundo parâmetro é um objeto de configuração gerado por odb_config.
Ao escrever uma solicitação de importação, verifique os documentos da API POST para entender quais colunas podem ser declaradas no data.frame.
Todas as funções de importação retornam um id do job, que pode ser usado para verificar se o job ainda está em execução, se terminou com sucesso ou se encontrou um erro. O log da execução pode ser acessado usando as funções odb_get_jobs() e odb_get_affected_ids(). Você também pode ver o log em sua lista de trabalhos do usuário na interface da web.
- Ordem é importante - a importação correta de dados pode depender de registros já registrados. Por exemplo, importar um indivíduo com uma identidade de táxon requer o nome do táxon registrado no banco de dados, então primeiro valide sua lista de táxons usando a API GET e, em seguida, importe os registros para o Indivíduos.
- Você pode Validar Coordenadas geográficas, detectando localidades cadastradas numa base OpenDataBio para geometrias de pontos
Trabalhando com datas e datas incompletas
Para Indivíduos, Vouchers e identificações, você pode usar datas incompletas.
O formato de data usado no OpenDataBio é AAA-MM-DD (ano - mês - dia), portanto, uma entrada válida seria 2018-05-28.
Particularmente em dados históricos, o dia (ou mês) exato pode não ser conhecido, então você pode substituir esses campos por NA: ‘1979-05-NA’ significa “um dia desconhecido, em maio de 1979” e ‘1979-NA- NA ‘significa “dia e mês desconhecidos, 1979”. Você não pode adicionar uma data para a qual tenha apenas o dia, mas pode, se tiver apenas o mês, se for realmente significativo de alguma forma.
6.2.1 - Importar Localidades
OpenDataBio é distribuído com um conjunto de dados de localidades para o Brasil, que inclui estados, municípios, unidades de conservação federais, terras indígenas e os biomas.
Trabalhar com dados espaciais é uma área delicada, por isso tentamos tornar o fluxo de trabalho para inserir Localidades o mais fácil possível.
Se você deseja fazer upload dos limites administrativos de um país, você também pode baixar um arquivo geojson em OSM-Boundaries e carregue-o diretamente através da interface da web. Ou use o repositório GADM exemplificado abaixo.
A importação é direta, mas os principais problemas a serem considerados:
- OpenDataBio armazena as geometrias de localidades usando representação de texto conhecido (WKT).
- As localidades são hierárquicas, portanto, uma localidade DEVE estar completamente dentro de sua localidade pai. O método de importação tentará detectar as localidades pai com base em sua geometria. Portanto, você não precisa informar um pai. No entanto, às vezes a localidade pai e a localidade filho compartilham uma borda ou têm pequenas erros que evitam a detecção. Portanto, se a importação não colocar o local onde você esperava, pode-se atualizar ou importar informando o pai correto. Quando você informar a localidade pai, uma segunda verificação será realizada adicionando um buffer à localidade pai e deverá resolver o problema.
- Os polígonos de países podem ser importados sem detecção ou definição dos pais, e registros marítimos podem ser vinculados a um pai, mesmo que não estejam contidos no polígono pai. Isso requer informar um campo específico (
ismarine) e deve ser usado nestes casos. - Padronizar a geometria para uma projeção comum de uso no sistema. Fortemente recomendado o uso de EPSG:4326 WGS84. Padronize antes de importar.
- Considere enviar seus polígonos político-administrativos antes de adicionar PONTOS, PLOTS ou TRANSECTOS específicos;
- Unidades de Conservação, Territórios Indígenas e Camadas Ambientais podem ser adicionados como locais e serão tratados como casos especiais, pois alguns desses locais abrangem diferentes unidades administrativas. Portanto, uma localidade de tipo POINT, PLOT ou TRANSECTpode pertencer a umA UC, umA TI e muitas camadas ambientais se estas estiverem armazenadas no banco de dados. Essas localidades relacionadas são detectadas automaticamente a partir da geometria da localidade.
Verifique a POST API de localidades para entender quais colunas podem ser declaradas ao importar localidades.
Adm_level define o tipo de localidade
O nível administrativo (adm_level) de um local é um número:
2para país;3à10como outras como ‘áreas administrativas’, seguindo a convenção OpenStreeMap para facilitar a importação de dados externos e traduções locais (À SER IMPLEMENTADO) . Portanto, para o Brasil, os códigos são (Estados = 4, Municípios = 8);999para locais de ‘POINT’ como waypoints GPS;101para transectos100é o código para PARCELAS e SUBPARCELAS;99é o código para Unidades de Conservação98para Territórios Indígenas97para polígonos ambientais (por exemplo, Floresta Ombrofila Densa ou Bioma Amazônia)
Importando polígonos espaciais
Limites administrativos do GADM
Limites administrativos também podem ser importados sem sair de R, obtendo dados de GDAM e usando as funções odb_import*
library(raster)
library(opendatabio)
#download áreas administrativas do GADM para um país
#get country codes
crtcodes = getData('ISO3')
bra = crtcodes[crtcodes$NAME%in%"Brazil",]
#define a path where to save the downloaded spatial data
path = "GADMS"
dir.create(path,showWarnings = F)
#o número de admin_levels em cada país varia
#obter todos os níveis existentes em seu computador
runit =T
level = 0
while(runit) {
ocrt <- try(getData('GADM', country=bra, level=level,path=path),silent=T)
if (class(ocrt)=="try-error") {
runit = FALSE
}
level = level+1
}
#read downloaded data and format to odb
files = list.files(path, full.name=T)
locations.to.odb = NULL
for(f in 1:length(files)) {
ocrt <- readRDS(files[f])
#class(ocrt)
#convert the SpatialPolygonsDataFrame to OpenDataBio format
ocrt.odb = opendatabio:::sp_to_df(ocrt) #only for GADM data
locations.to.odb = rbind(locations.to.odb,ocrt.odb)
}
#see without geometry
head(locations.to.odb[,-ncol(locations.to.odb)])
#you may add a note to location
locations.to.odb$notes = paste("Source gdam.org via raster::get_data()",Sys.Date())
#adjust the adm_level to fit the OpenStreeMap categories
ff = as.factor(locations.to.odb$adm_level)
(lv = levels(ff))
levels(ff) = c(2,4,8,9)
locations.to.odb$adm_level = as.vector(ff)
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
odb_import_locations(data=locations.to.odb,odb_cfg=cfg)
Atenção: você pode querer verificar se há exclusividade de nome + pai em vez de apenas nome, já que nome + pai é uma combinação única. Você não pode salvar dois locais com o mesmo nome dentro do mesmo pai.
Example usando um shapefile
library(rgdal)
#read your shape file
path = 'mymaps'
file = 'myshapefile.shp'
layer = gsub(".shp","",file,ignore.case=TRUE)
data = readOGR(dsn=path, layer= layer)
#you may reproject the geometry to standard of your system if needed
data = spTransform(data,CRS=CRS("+proj=longlat +datum=WGS84"))
#convert polygons to WKT geometry representation
library(rgeos)
geom = rgeos::writeWKT(data,byid=TRUE)
#prep import
names = data@data$name #or the column name of the data
shape.to.odb = data.frame(name=names,geom=geom,stringsAsFactors = F)
#need to add the admin_level of these locations
shape.to.odb$admin_level = 2
#and may add parent and note if your want
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
odb_import_locations(data=shape.to.odb,odb_cfg=cfg)
Example importando de um KML
#read file as SpatialPolygonDataFrame
file = "myfile.kml"
file.exists(file)
mykml = readOGR(file)
geom = rgeos::writeWKT(mykml,byid=TRUE)
#prep import
names = mykml@data$name #or the column name of the data
to.odb = data.frame(name=names,geom=geom,stringsAsFactors = F)
#need to add the admin_level of these locations
to.odb$admin_level = 2
#and may add parent or any other valid field
#import
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
odb_import_locations(data=to.odb,odb_cfg=cfg)
Importar Parcelas e SubParcelas
Parcelas e transectos são casos especiais no OpenDataBio:
- Eles podem ser definidas com uma geometria do tipo Polygon ou LineString, respectivamente;
- Ou eles podem ser registrados apenas como localidaes de tipo POINT. Nesse caso, o OpenDataBio criará o polígono ou linestring para você;
- Dimensões (x e y) são armazenadas em metros para PARCELAS. Portanto elas devem ser quadradas ou retangulares.
- SubParcelas são localidades do tipo PARCELA tendo outra localidade do tipo PARCELA como pai e também devem ter posições cartesianas (startX, startY) dentro da localidade pai além das dimensões. A posição cartesiana refere-se às posições X e Y dentro da PARCELA pai e, portanto, DEVE ser menor do que o pai X e Y.
- SubParcela é o único tipo de localidade que pode ser registrado sem uma coordenada geográfica ou geometria, que será calculada a partir da geometria da PARCELA pai usando os valores startx e starty.
Parcela e SubParcela - exemplo 01
Você precisa de pelo menos uma coordenada geográfica para registrar uma localidade do tipo PLOT. A geometria (ou latitude e longitude) não pode estar vazia.
Este exemplo registra uma parcela em Manaus de 100x100m, informando sua geometria e depois importa algumas subparcelas sem especificação de geometria.
#geometry of a plot in Manaus
southWestCorner = c(-59.987747, -3.095764)
northWestCorner = c(-59.987747, -3.094822)
northEastCorner = c(-59.986835,-3.094822)
southEastCorner = c(-59.986835,-3.095764)
geom = rbind(southWestCorner,northWestCorner,northEastCorner,southEastCorner)
library(sp)
geom = Polygon(geom)
geom = Polygons(list(geom), ID = 1)
geom = SpatialPolygons(list(geom))
library(rgeos)
geom = writeWKT(geom)
to.odb = data.frame(name='A 1ha example plot',x=100,y=100,notes='a fake plot',geom=geom, adm_level = 100,stringsAsFactors=F)
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
odb_import_locations(data=to.odb,odb_cfg=cfg)
Aguarde alguns segundos e, em seguida, importe subtramas para esta plotagem.
#importar subparcelas de 20x20m para a PARCELA acima sem indicar uma geometria.
(parent = odb_get_locations(params = list(name='A 1ha example plot',fields='id,name',adm_level=100),odb_cfg = cfg))
sub1 = data.frame(name='sub plot 40x40',parent=parent$id,x=20,y=20,adm_level=100,startx=40,starty=40,stringsAsFactors=F)
sub2 = data.frame(name='sub plot 0x0',parent=parent$id,x=20,y=20,adm_level=100,startx=0,starty=0,stringsAsFactors=F)
sub3 = data.frame(name='sub plot 80x80',parent=parent$id,x=20,y=20,adm_level=100,startx=80,starty=80,stringsAsFactors=F)
dt = rbind(sub1,sub2,sub3)
#import
odb_import_locations(data=dt,odb_cfg=cfg)
Capturas de tela das parcelas importadas
Abaixo capturas de tela para as parcelas importadas com o código acima
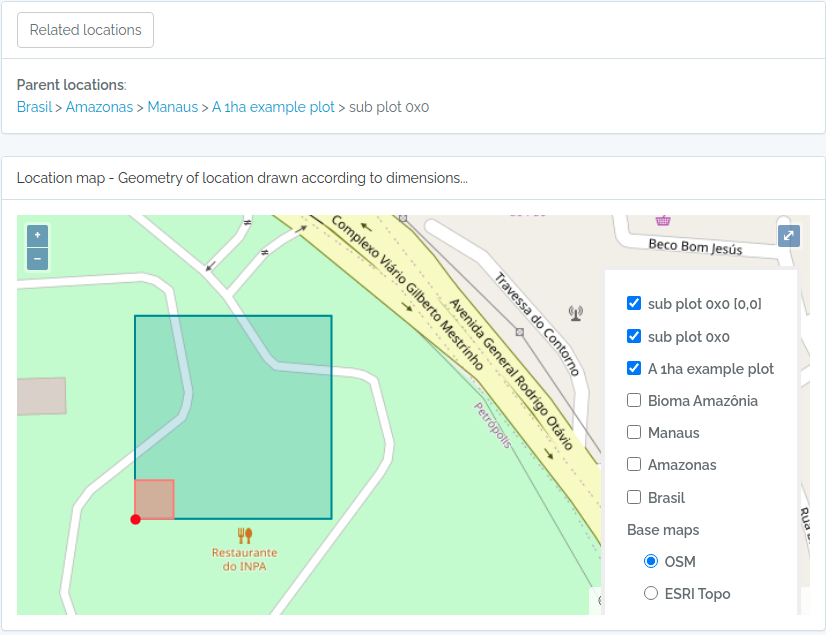
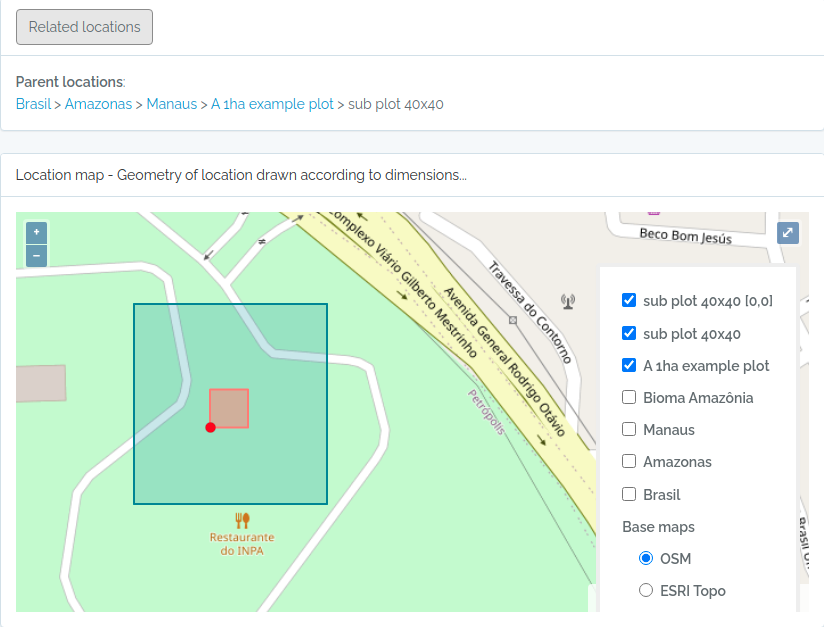
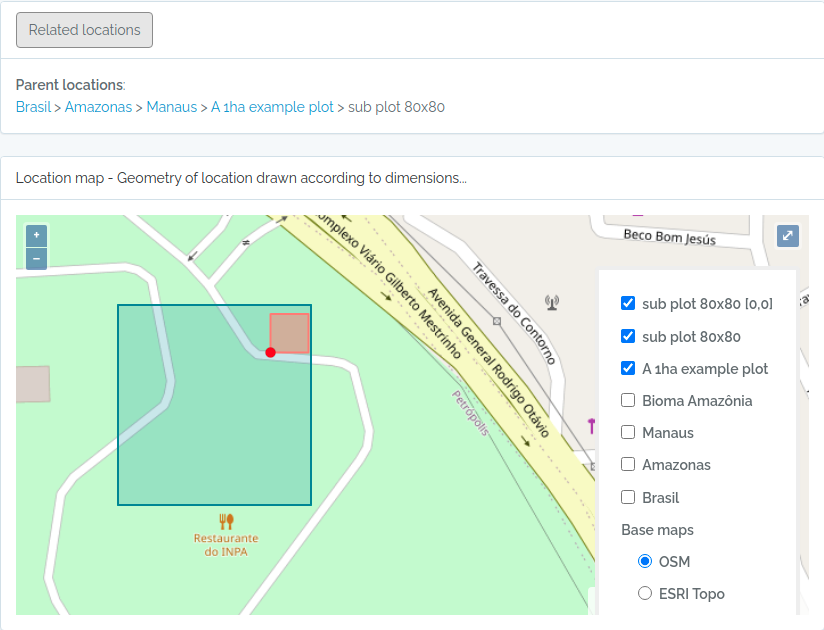
Parcela e SubParcela - exemplo 02
Importe uma parcela e suas subparcelas tendo apenas:
- a coordenada geográfica de um único ponto, representando a coordenada [0,0] da parcela.
- um azimute ou ângulo da direção da parcela (se não informar, Norte será usado
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
#the plot
geom = "POINT(-59.973841 -2.929822)"
to.odb = data.frame(name='Example Point PLOT',x=100, y=100, azimuth=45,notes='OpenDataBio point plot example',geom=geom, adm_level = 100,stringsAsFactors=F)
odb_import_locations(data=to.odb,odb_cfg=cfg)
#define 20x20 subplots cartesian coordinates
x = seq(0,80,by=20)
xx = rep(x,length(x))
yy = rep(x,each=length(x))
names = paste(xx,yy,sep="x")
#importar esses subplots sem ter uma geometria, mas especificando a localidade pai
parent = odb_get_locations(params = list(name='Example Point PLOT',adm_level=100),odb_cfg = cfg)
to.odb = data.frame(name=names,startx=xx,starty=yy,x=20,y=20,notes="OpenDataBio 20x20 subplots example",adm_level=100,parent=parent$id)
odb_import_locations(data=to.odb,odb_cfg=cfg)
#obter os locais importados usando o parâmetro root
locais = odb_get_locations(params=list(root=parent$id),odb_cfg = cfg)
locais[,c('id','locationName','parentName')]
colnames(locais)
for(i in 1:nrow(locais)) {
geom = readWKT(locais$footprintWKT[i])
if (i==1) {
plot(geom,main=locais$locationName[i],cex.main=0.8,col='yellow')
axis(side=1,cex.axis=0.7)
axis(side=2,cex.axis=0.7,las=2)
} else {
plot(geom,add=T,border='red')
}
}
A figura gerada acima:
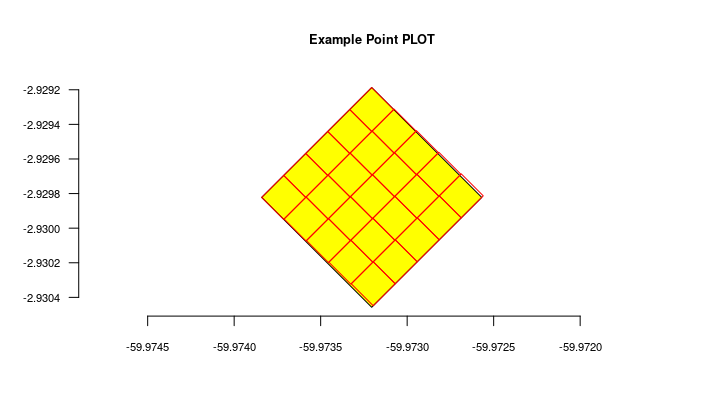
Importar transectos
Este código importará dois transectos, um definido por uma geometria (LINESTRING), e o outro apenas por uma única coordenada geográfica (POINT). Veja as figuras abaixo para o resultado importado.
#geometry of transect in Manaus
#read trail from a kml file
#library(rgdal)
#file = "acariquara.kml"
#file.exists(file)
#mykml = readOGR(file)
#library(rgeos)
#geom = rgeos::writeWKT(mykml,byid=TRUE)
#above will output:
geom = "LINESTRING (-59.9616459699999993 -3.0803612500000002, -59.9617394400000023 -3.0805952900000002, -59.9618530300000003 -3.0807376099999999, -59.9621049400000032 -3.0808563200000001, -59.9621949100000009 -3.0809758500000002, -59.9621587999999974 -3.0812666800000001, -59.9621092399999966 -3.0815010400000000, -59.9620656999999966 -3.0816403499999998, -59.9620170600000009 -3.0818584699999998, -59.9620740699999999 -3.0819864099999998)";
#prep data frame
#o valor y refere-se a um buffer em metros aplicado à trilha
#y é usado para validar a inserção de indivíduos relacionados
to.odb = data.frame(name='A trail-transect example',y=20, notes='OpenDataBio transect example',geom=geom, adm_level = 101,stringsAsFactors=F)
#import
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
odb_import_locations(data=to.odb,odb_cfg=cfg)
#IMPORTA UM SEGUNDO TRANSECTO SEM GEOMETRIA
# então você precisa informar o valor x, que é o comprimento do transecto
#ODB irá mapear este transecto orientado pelo parâmetro azimute (sul no exemplo abaixo)
#point geometry = ponto inicial
geom = "POINT(-59.973841 -2.929822)"
to.odb = data.frame(name='A transect point geometry',x=300, y=20, azimuth=180,notes='OpenDataBio point transect example',geom=geom, adm_level = 101,stringsAsFactors=F)
odb_import_locations(data=to.odb,odb_cfg=cfg)
locais = odb_get_locations(params=list(adm_level=101),odb_cfg = cfg)
locais[,c('id','locationName','parentName','levelName')]
O código acima resultará nas duas localidades a seguir:
![]()
![]()
6.2.2 - Importar BibReferences
#sua conexao
library(opendatabio)
base_url="http://localhost/opendatabio/api"
token ="O SEU TOKEN AQUI"
cfg = odb_config(base_url=base_url, token = token)
odb_test(cfg)
#leia no R as referencias bibliograficas
library(rbibutils)
bibs = readBib(file="yourFileWithReferences.bib")
formatbib <- function(x) {
con <- textConnection("bibref", "w")
writeBib(x,con=con)
bibref = paste(bibref,collapse = " ")
close(con)
return(bibref)
}
#prepara para importar ao odb
bibtexts = sapply(bibs,formatbib)
data = data.frame(bibtex=bibtexts,standardize=1,stringsAsFactors = F)
#importa
jobid = odb_import_bibreferences(data,odb_cfg = cfg)
#aguarda finalizacao
odb_get_jobs(params=list(id=jobid$id),odb_cfg = cfg)
#pega o log da importacao
dt = odb_get_affected_ids(job_id=jobid$id,odb_cfg = cfg)
6.2.3 - Importar Vernacular
library(opendatabio)
base_url="http://localhost/opendatabio/api"
token ="O SEU TOKEN AQUI"
cfg = odb_config(base_url=base_url, token = token)
odb_test(cfg)
#gerar um dado fake para teste
name = c('pau rosa',"casca preciosa")
taxons = c("Aniba roseaodora,Aniba panurensis,Aniba parvifolia","Aniba canelilla")
#pega o id de alguns individuos
inds = odb_get_individuals(params=list(taxon="Aniba roseaodora,Aniba panurensis,Aniba parvifolia",fields='id,scientificName',limit=10),odb_cfg = cfg)
individuals=c(paste(inds$id,collapse = ","),NA)
idiomas = odb_get_languages(odb_cfg = cfg)
language= c('pt-br','en')
#cria um data.frame com essas informacoes
verna = data.frame(name,taxons,language,taxons,individuals)
#citatcoes (basta gerar um data.frame para cada vernacular)
umaCitatcao = data.frame(
citation='Este seria o texto citado',
bibreference="Riberiroetal1999FloraDucke", #bibkey ou o id
type='generic', #pode ser: generic, use, etimology
notes='minhas observações sobre essa citação')
#adiciona uma coluna do tipo lista
verna$citations = list(umaCitatcao,NA)
#importar para o opendatabio
odb_import_vernaculars(verna,odb_cfg = cfg)
6.2.4 - Importar Media
- Você precisa basicamente dos arquivos de mídia em uma única pasta e uma tabela que tem os atributos de cada arquívo de mídia;
- Ver o POST Media API docs para entender quais colunas podem ser declaradas ao importar Mídia. Apenas 3 colunas são obrigatórias na tabela de atributos:
filename,object_typeeobject_id, mas é importante informar outras coisas sobre o arquivo, como data, autores, título, licensa de uso, conjunto de dados e também Tags. - Considere adicionar pelo menos 1 palavra chave (Tag) para cada mídia
Importanto mídia através da API
O método abaixo pode ser feito tanto pela API usando o pacote do R, como pela interface web. Teste e use o que for mais rápido para enviar os arquivos de imagem.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url)
#caminho do folder onde estao as imagens
folder = 'imagesParaOdb'
#vejas os nomes
filenames = dir(folder,full.names=F)
#tabela de atributos
atributos = read.table('arquivoAtributos.csv',sep=',',header=T,as.is=T,na.strings=c("","NA","-"))
#todos arquivos estao na tabela de atributos?
print(paste(sum( filenames %in% atributos$filename ),"de",length(filenames),'arquivos estão listados na tabela de atributos'))
#importa para o odb
odb_upload_media_zip(folder=folder,attribute_table = atributos,odb_cfg = cfg)
6.2.5 - Importar Taxons
- Para uma importação bem-sucedida de nomes taxomicos publicados você só precisa fornecer um
name, sendo o nome completo para espécies e infra-espécies (por exemplo, Licaria canella tenuicarpa, Ocotea delicata), da mesma forma quecanonicalNamedo GBIF, ou seja, não inclui os ranks infra-específicos; - Não há necessidade de importar táxons pais para nomes publicados, OpenDataBio faz isso para você. O processo de importação usará o
nameque você informou para recuperar informações de táxons de um repositório de nomenclatura: atualmente Tropicos, GBIF BackBone Taxonomy e ZOOBANK. Se o nome do táxon for encontrado, ele obterá automaticamente as informações necessárias e também todos os táxons pais (ou nomes aceitos se estiver marcado como sinônimo) conforme necessário, e armazenará no banco de dados para você. Se onamefor inválido, ou seja, é sinônimo de outro nome, ele será importado, mas marcado como inválido. - Se informar
parente for diferente do detectado pela API o pai informado tem preferência. - Para espécies não publicadas
level,parent, e umapersonouauthor_idtambém devem ser fornecidos; - A API externa usará uma consulta difusa durante a pesquisa de GBIF se não encontrar uma correspondência exata, permitindo detectar até mesmo quando está com erros ortográficos. No entanto, erros de grafia nos nomes podem impedir que um táxon seja armazenado.
- A taxonomia é hierárquica e a estrutura dentro do OpenDataBio pode ser semelhante a uma árvore. Portanto, você pode adicionar, se quiser, qualquer nó da árvore da vida na tabela Taxon. Para isso, você precisa usar o nível do táxon
Clade. Mas observe que isso pode não ser relevante se você não vincular dados a esses nomes de clados. - Como a verificação da nomenclatura é demorada, seja paciente.
OpenDataBio é distribuído com uma tabela semente de Taxons, que inclui a raiz de todos os reinos e alguns nós da filogenia das plantas, ou seja, o os nós da àrvore no nível de ordem para Angiospermas - APWeb Tree.
Um exemplo simples de nome publicado
Os scripts abaixo foram testados, estando a base já populada com até o nível de Ordem para Angiospermas.
Na tabela de táxons, as famílias Moraceae, Lauraceae e Solanaceae ainda não estavam registradas:
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
cfg = odb_config(base_url=base_url)
exists = odb_get_taxons(params=list(root="Moraceae,Lauraceae,Solanaceae"),odb_cfg=cfg)
Retornou:
data frame with 0 columns and 0 rows
Agora importe algumas espécies e uma infraespécie para as famílias acima, especificando seu nome completo (canonicalName):
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
spp = c("Ficus schultesii", "Ocotea guianensis","Duckeodendron cestroides","Licaria canella tenuicarpa")
splist = data.frame(name=spp)
odb_import_taxons(splist, odb_cfg=cfg)
Agora verifique se foi importado (note o argumento root):
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
cfg = odb_config(base_url=base_url)
exists = odb_get_taxons(params=list(root="Moraceae,Lauraceae,Chrysobalanaceae"),odb_cfg=cfg)
head(exists[,c('id','scientificName', 'taxonRank','taxonomicStatus','parentNameUsage')])
Retorno:
id scientificName taxonRank taxonomicStatus parentName
1 252 Moraceae Family accepted Rosales
2 253 Ficus Genus accepted Moraceae
3 254 Ficus schultesii Species accepted Ficus
4 258 Solanaceae Family accepted Solanales
5 259 Duckeodendron Genus accepted Solanaceae
6 260 Duckeodendron cestroides Species accepted Duckeodendron
7 255 Lauraceae Family accepted Laurales
8 256 Ocotea Genus accepted Lauraceae
9 257 Ocotea guianensis Species accepted Ocotea
10 261 Licaria Genus accepted Lauraceae
11 262 Licaria canella Species accepted Licaria
12 263 Licaria canella subsp. tenuicarpa Subspecies accepted Licaria canella
Observe que embora tenhamos especificado apenas os nomes das espécies e infra-espécies, a API importou também toda a hierarquia parental necessária até a família, porque as ordens já estavam registradas.
Um exemplo de nome publicado inválido
O nome Licania octandra pallida (Chrysobalanaceae) foi recentemente movido com sinônimo de Leptobalanus octandrus pallidus.
O roteiro a seguir exemplifica o que acontece nesses casos.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
#lets check
exists = odb_get_taxons(params=list(root="Chrysobalanaceae"),odb_cfg=cfg)
exists
#in this test returns an empty data frame
#data frame with 0 columns and 0 rows
#now import
spp = c("Licania octandra pallida")
splist = data.frame(name=spp)
odb_import_taxons(splist, odb_cfg=cfg)
#see the results
exists = odb_get_taxons(params=list(root="Chrysobalanaceae"),odb_cfg=cfg)
exists[,c('id','scientificName', 'taxonRank','taxonomicStatus','parentName')]
Retorno:
id scientificName taxonRank taxonomicStatus parentName
1 264 Chrysobalanaceae Family accepted Malpighiales
2 265 Leptobalanus Genus accepted Chrysobalanaceae
3 267 Leptobalanus octandrus Species accepted Leptobalanus
4 269 Leptobalanus octandrus subsp. pallidus Subspecies accepted Leptobalanus octandrus
5 266 Licania Genus accepted Chrysobalanaceae
6 268 Licania octandra Species invalid Licania
7 270 Licania octandra subsp. pallida Subspecies invalid Licania octandra
Observe que, embora tenhamos especificado apenas um nome de infra-espécie, a API importou também toda a hierarquia pai necessária até a família e, como o nome é inválido, também importou o nome aceito para esta infra-espécie e seus pais.
Uma espécie ou morfotipo não publicado
É comum ter nomes de espécies locais não publicados (morfotipos) para plantas em parcelas, ou ainda trabalhos taxonômicos ainda não publicados. As designações não publicadas são específicas do projeto e, portanto, DEVEM também fornecer um autor, pois diferentes projetos podem usar o mesmo código ‘sp.1’ ou ‘sp.A’ para seus táxons não publicados.
Você pode vincular um nome não publicado como qualquer nível de táxon e não precisa usar a lógica de gênero + espécie para atribuir um morfotipo para o qual o gênero ou taxonomia de nível superior é indefinida. Por exemplo, você pode armazenar um nível de ’espécie’ com o nome ‘Indet sp.1’ e parent_name ‘Laurales’, se a determinação formal de nível mais baixo que você tem é o nível de ordem. Neste exemplo, não há necessidade de armazenar um gênero Indet e táxons da família Indet apenas para contabilizar este morfotipo não identificado.
##assign an unpublished name for which you only know belongs to the Angiosperms and you have this node in the Taxon table already
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
cfg = odb_config(base_url=base_url)
#check that angiosperms exist
odb_get_taxons(params=list(name='Angiosperms'),odb_cfg = cfg)
#if it is there, start creating a data.frame to import
to.odb = data.frame(name='Morphotype sp.1', parent='Angiosperms', stringsAsFactors=F)
#get species level numeric code
to.odb$level=odb_taxonLevelCodes('species')
#you must provide an author that is a Person in the Person table. Get from server
odb.persons = odb_get_persons(params=list(search='João Batista da Silva'),odb_cfg=cfg)
#found
head(odb.persons)
#add the author_id to the data.frame
#NOTE it is not author, but author_id or person)
#this makes odb understand it is an unpublished name
to.odb$author_id = odb.persons$id
#import
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
odb_import_taxons(to.odb,odb_cfg = cfg)
Verifique o registro importado:
exists = odb_get_taxons(params=list(name='Morphotype sp.1'),odb_cfg = cfg)
exists[,c('id','scientificName', 'taxonRank','taxonomicStatus','parentName','scientificNameAuthorship')]
Algumas colunas para o registro importado:
id scientificName taxonRank taxonomicStatus parentName scientificNameAuthorship
1 276 Morphotype sp.1 Species unpublished Angiosperms João Batista da Silva - Silva, J.B.D.
Importar um clado publicado
Você pode adicionar um clado Taxon e pode referenciar uma publicação usando a entrada bibkey. Portanto, é possível armazenar de fato todos os nós relevantes de qualquer filogenia na hierarquia do Taxon.
#parent já deve estar armazenado
odb_get_taxons(params=list(name='Pagamea'),odb_cfg = cfg)
#define o clado a ser armazenado
to.odb = data.frame(name='Guianensis core', parent_name='Pagamea', stringsAsFactors=F)
to.odb$level = odb_taxonLevelCodes('clade')
#adicione uma referência à publicação onde está publicado
#importe a referência do bib para o banco de dados de antemão
odb_get_bibreferences(params(bibkey='prataetal2018'),odb_cfg=cfg)
to.odb$bibkey = 'prataetal2018'
#então adicione nomes de espécies válidos como filhos deste clado em vez do nível de gênero
children = data.frame(name = c('Pagamea guianensis','Pagamea angustifolia','Pagamea puberula'),stringsAsFactors=F)
children$parent_name = 'Guianensis core'
children$level = odb_taxonLevelCodes('species')
children$bibkey = NA
#merge
to.odb = rbind(to.odb,children)
#import
odb_import_taxons(to.odb,odb_cfg = cfg)
6.2.6 - Importar Pessoas
Ver o POST Persons API docs para entender quais colunas podem ser declaradas ao importar Pessoas.
A API verificará por abreviações idênticas, que é a única restrição da classe Pessoa. Abreviações são exclusivas e duplicações não são permitidas. Isso não impede que os dados baixados de repositórios tenham abreviações ou nomes completos diferentes para a mesma pessoa. Portanto, você deve padronizar os dados secundários antes de importá-los para o servidor para minimizar esses erros comuns.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ"
cfg = odb_config(base_url=base_url, token = token)
one = data.frame(full_name='Adolpho Ducke',abbreviation='DUCKE, A.',notes='Grande botânico da Amazônia',stringsAsFactors = F)
two = data.frame(full_name='Michael John Gilbert Hopkins',abbreviation='HOPKINKS, M.J.G.',notes='Curador herbário INPA',stringsAsFactors = F)
to.odb= rbind(one,two)
odb_import_persons(to.odb,odb_cfg=cfg)
#pode adicionar um email
Pegar os dados
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
cfg = odb_config(base_url=base_url)
persons = odb_get_persons(odb_cfg=cfg)
persons = persons[order(persons$id,decreasing = T),]
head(persons,2)
resultado:
id full_name abbreviation email institution notes
613 1582 Michael John Gilbert Hopkins HOPKINKS, M.J.G. <NA> NA Curador herbário INPA
373 1581 Adolpho Ducke DUCKE, A. <NA> NA Grande botânico da Amazônia
6.2.7 - Importar Variáveis
- Recomendamos fortemente que você use a interface da web para inserir variáveis uma por uma. Use importações em lote somente se você tiver muitas variáveis.
- Antes de importar qualquer variável certifique-se de que ela já não esteja cadastrada no sistema com um nome diferente. Prevenir a duplicação é importante porque a classe Trait é compartilhada entre todos os usuários de uma instalação OpenDataBio. Isso também significa que, uma vez que uma variável é usada para Medições, você só poderá alterar a definição da variável, por exemplo, um nome de uma categoria, se você for o único usuário que inseriu medições para a variável. Caso contrário, outra pessoa usou essa definição e você não poderá alterá-la.
- export_name deve ser exclusivo em uma única instalação ODB. Este nome é usado ao exportar dados e em formulários, e você deve considerar torná-lo o mais curto e informativo (de definição) possível. Além disso, a API validará o nome da exportação - deve ser camelCase, PascalCase ou snake_case, e você não pode adicionar espaços ou qualquer caractere especial (acentos). Ex. ‘dbh’, ‘dbhPom’, ’leafLength’, ‘LeafLength’ ou ’leaf_length’, respectivamente.
As características podem ser importadas usando odb_import_traits().
Leia atentamente o Traits POST API.
Tipos de variáveis
Veja odb_traitTypeCodes() para os códigos numéricos possíveis tipos de variáveis
Traduções Nome da Variável e de Categorias
Os campos name e description podem ter um dos seguintes conteúdos:
- usando o código do idioma como chaves:
list("en" = "Diameter at Breast Height","pt-br" ="Diâmetro a Altura do Peito") - ou usando os nomes dos idiomas como chaves:
list("English" ="Diameter at Breast Height","Portuguese" ="Diâmetro a Altura do Peito").
O campo categories deve incluir para cada categoria + classificação + idioma os seguintes campos: lang= misto - obrigatório, o id, código ou nome do idioma da traduçãoname= string - obrigatório, o nome da categoria traduzido obrigatório (name + rank + lang deve ser único)rank= número - obrigatório, a classificação é importante para indicar a mesma categoria entre os idiomas e define variáveis ordinais;description= string - opcional para categorias, uma definição da categoria.
Isso pode ser formatado como um data.frame e colocado na coluna categories de outro data.frame:
data.frame(
rbind(
c("lang"="en","rank"=1,"name"="small","description"="smaller than 1 cm"),
c("lang"="pt-br","rank"=1,"name"="pequeno","description"="menor que 1 cm"),
c("lang"="en","rank"=2,"name"="big","description"="bigger than 10 cm"),
c("lang"="pt-br","rank"=2,"name"="grande","description"="maior que 10 cm")
),
stringsAsFactors=FALSE
)
Variável quantitativa
Para variáveis quantitativas para valores integers ou real (type 0 ou 1).
odb_traitTypeCodes()
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#do this first to build a correct data.frame as it will include translations list
to.odb = data.frame(type=1,export_name = "dbh", unit='centimeters',stringsAsFactors = F)
#add translations (note double list)
#format is language_id = translation (and the column be a list with the translation lists)
to.odb$name[[1]]= list('1' = 'Diameter at breast height', '2' = 'Diâmetro à altura do peito')
to.odb$description[[1]]= list('1' = 'Stem diameter measured at 1.3m height','2' = 'Diâmetro do tronco medido à 1.3m de altura')
#measurement validations
to.odb$range_min = 10 #this will restrict the minimum measurement value allowed in the trait
to.odb$range_max = 400 #this will restrict the maximum value
#measurements can be linked to (classes concatenated by , or a list)
to.odb$objects = "Individual,Voucher,Taxon" #makes no sense link such measurements to Locations
to.odb$notes = 'this is quantitative trait example'
#import
odb_import_traits(to.odb,odb_cfg=cfg)
Variável categórica
- Deve incluir categorias. A única diferença entre as características ordinais e categóricas é que as categorias ordinais terão um rank, ou ordem. Observe que as variáveis ordinais são semiquantitativas e, portanto, se você tiver categorias, pergunte-se se elas não são realmente ordinais e registre de acordo.
- Assim como o
namee adescriptionda variável, as categorias também podem ter traduções em diferentes idiomas, e você DEVE inserir as traduções para os idiomas disponíveis (odb_get_languages ()) para que a variável esteja acessível em todos os idiomas. O inglês é obrigatório, portanto, pelo menos o nome em inglês deve ser informado. As categorias podem ter uma descrição associada, mas às vezes o nome da categoria é autoexplicativo, portanto, as descrições das categorias não são obrigatórias.
odb_traitTypeCodes()
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#do this first to build a correct data.frame as it will include translations list
#do this first to build a correct data.frame as it will include translations list
to.odb = data.frame(type=3,export_name = "specimenFertility", stringsAsFactors = F)
#trait name and description
to.odb$name = data.frame("en"="Specimen Fertility","pt-br"="Fertilidade do especímene",stringsAsFactors=F)
to.odb$description = data.frame("en"="Kind of reproductive stage of a collected plant","pt-br"="Estágio reprodutivo de uma amostra de planta coletada",stringsAsFactors=F)
#categories (if your trait is ORDINAL, the add categories in the wanted order here)
categories = data.frame(
rbind(
c('en',1,"Sterile"),
c('pt-br',1,"Estéril"),
c('en',2,"Flowers"),
c('pt-br',2,"Flores"),
c('en',3,"Fruits"),
c('pt-br',3,"Frutos"),
c('en',4,"Flower buds"),
c('pt-br',4,"Botões florais")
),
stringsAsFactors =FALSE
)
colnames(categories) = c("lang","rank","name")
#descriptions not included for categories as they are obvious,
# but you may add a 'description' column to the categories data.frame
#objects for which the trait may be used for
to.odb$objects = "Individual,Voucher"
to.odb$notes = 'a fake note for a multiselection categorical trait'
to.odb$categories = list(categories)
#import
odb_import_traits(to.odb,odb_cfg=cfg)
Variável tipo LINK
Um variável de tipo LINK permite vincular um Táxon ou Voucher como uma medição de outro objeto. Por exemplo, você pode conduzir um inventário de plantas para o qual possui apenas contagens para o táxon associado a uma localidade. Portanto, você pode criar uma variável do tipo LINK, que permitirá que você armazene os valores de contagem para qualquer Táxon como medições para um local específico (PONTO, POLÍGONO).
Use a interface ou siga o exemplo para as demais variáveis.
Variáveis do tipo texto ou cor
Variáveis de texto permitem o armazenamento de observações textuais. A cor permitirá apenas códigos de cores.
odb_traitTypeCodes()
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
to.odb = data.frame(type=5,export_name = "taxonDescription", stringsAsFactors = F)
#trait name and description
to.odb$name = data.frame("en"="Taxonomic descriptions","pt-br"="Descrições taxonômicas",stringsAsFactors=F)
to.odb$description = data.frame("en"="Taxonomic descriptions from the literature","pt-br"="Descrições taxonômicas da literatura",stringsAsFactors=F)
#will only be able to use this trait for a measurment associated with a Taxon
to.odb$objects = "Taxon"
#import
odb_import_traits(to.odb,odb_cfg=cfg)
Variáveis espectrais
Variáveis espectrais são específicos para dados espectrais. Você deve especificar a amplitude dos números de ondas para os quais você pode ter dados de absorbância ou refletância e o comprimento dos espectros a serem armazenados como medições para permitir a validação durante a entrada. Portanto, para cada intervalo e espaçamento dos valores espectrais que você tem, uma variável ESPECTRAL diferente deve ser criada.
Use a interface ou siga o exemplo para as demais variáveis.
6.2.8 - Importar Indivíduos & Vouchers
- Você pode importar Vouchers juntamente com o registro do Indivíduo. Use o endpoint POST-Voucher apenas para indivíduos já registrados, caso contrário, siga abaixo para importar indivíduos e seus vouchers de uma só vez.
- Os indivíduos podem ter uma identificação taxonômica própria ou uma identificação taxonômica dependente
- Os indivíduos podem ter vários locais, mas ao registrar o indivíduo, um único local é necessário. Você pode então importar locais adicionais usando o Individual-location POST API.
Indivíduos podem ser importados usando odb_import_individuals() e vouchers com odb_import_vouchers().
Leia atentamente o Individual POST API e o Voucher POST API.
Exemplo simples
Inventando dados para 1 registro de um indivíduo:
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#the number in the aluminium tag in the forest
to.odb = data.frame(tag='3405.L1', stringsAsFactors=F)
#the collectors (get ids from the server)
(joao = odb_get_persons(params=list(search='joao batista da silva'),odb_cfg=cfg)$id)
(ana = odb_get_persons(params=list(search='ana cristina sega'),odb_cfg=cfg)$id)
#ids concatenated by | pipe
to.odb$collector = paste(joao,ana,sep='|')
#tagged date (lets use an incomplete).
to.odb$date = '2018-07-NA'
#lets place in a Plot location imported with the Location post tutorial
plots = odb_get_locations(params=list(name='A 1ha example plot'),odb_cfg=cfg)
head(plots)
to.odb$location = plots$id
#relative position within parent plot
to.odb$x = 10.4
to.odb$y = 32.5
#or could be
#to.odb$relative_position = paste(x,y,sep=',')
#taxonomic identification
taxon = 'Ocotea guianensis'
#check that exists
(odb_get_taxons(params=list(name='Ocotea guianensis'),odb_cfg=cfg)$id)
#person that identified the individual
to.odb$identifier = odb_get_persons(params=list(search='paulo apostolo'),odb_cfg=cfg)$id
#or you also do to.odb$identifier = "Assunção, P.A.C.L."
#the used form only guarantees the persons is there.
#may add modifers as well [may need to use numeric code instead]
to.odb$modifier = 'cf.'
#or check with to see you spelling is correct
odb_detModifiers()
#and submit the numeric code instaed
to.odb$modifier = 3
#an incomplete identification date
to.odb$identification_date = list(year=2005)
#or to.odb$identification_date = "2005-NA-NA"
Importando esse indivíduo
odb_import_individuals(to.odb,odb_cfg = cfg)
#lets import this individual
odb_import_individuals(to.odb,odb_cfg = cfg)
#check the job status
odb_get_jobs(params=list(id=130),odb_cfg = cfg)
Ops, esqueci de informar um dataset e meu usuário não tem um dataset default definido.
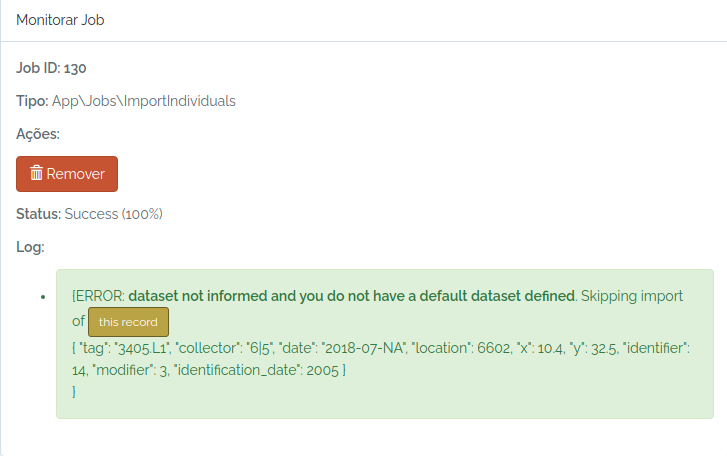
Então, eu apenas informo um conjunto de dados existente e tento novamente:
dataset = odb_get_datasets(params=list(name="Dataset test"),odb_cfg=cfg)
dataset
to.odb$dataset = dataset$id
odb_import_individuals(to.odb,odb_cfg = cfg)
Importando Indivíduos e Vouchers de uma vez
Indivíduos são o objeto real que possui a maior parte das informações relacionadas aos Vouchers, que são amostras em uma Biocoleção. Portanto, você pode importar um registro de um indivíduo com a especificação de um ou mais vouchers.
#a fake plant record somewhere in the Amazon
aplant = data.frame(taxon="Duckeodendron cestroides", date="2021-09-09", latitude=-2.34, longitude=-59.845,angle=NA,distance=NA, collector="Oliveira, A.A. de|João Batista da Silva", tag="3456-A",dataset=1)
#a fake set of vouchers for this individual
herb = data.frame(biocollection=c("INPA","NY","MO"),biocollection_number=c("12345A","574635","ANOTHER FAKE CODE"),biocollection_type=c(2,3,3))
#add this dataframe to the object
aplant$biocollection = NA
aplant$biocollection = list(herb)
#another fake plant
asecondplant = data.frame(taxon="Ocotea guianensis", date="2021-09-09", latitude=-2.34, longitude=-59.89,angle=240,distance=50, collector="Oliveira, A.A. de|João Batista da Silva", tag="3456",dataset=1)
asecondplant$biocollection = NA
#merge the fake data
to.odb = rbind(aplant,asecondplant)
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
odb_import_individuals(to.odb, odb_cfg=cfg)
Verifique os dados importados
O script acima criou registros para o modelo Indivíduo e Voucher:
#get the imported individuals using a wildcard
inds = odb_get_individuals(params = list(tag='3456*'),odb_cfg = cfg)
inds[,c("basisOfRecord","scientificName","organismID","decimalLatitude","decimalLongitude","higherGeography") ]
Retorna:
basisOfRecord scientificName organismID decimalLatitude decimalLongitude higherGeography
1 Organism Ocotea guianensis 3456 - Oliveira - UnnamedPoint_5989234 -2.3402 -59.8904 Brasil | Amazonas | Rio Preto da Eva
2 Organism Duckeodendron cestroides 3456-A - Oliveira - UnnamedPoint_5989234 -2.3400 -59.8900 Brasil | Amazonas | Rio Preto da Eva
E Vouchers
#get the vouchers imported with the first plant data
vouchers = odb_get_vouchers(params = list(individual=inds$id),odb_cfg = cfg)
vouchers[,c("basisOfRecord","scientificName","organismID","collectionCode","catalogNumber") ]
Retorna:
basisOfRecord scientificName occurrenceID collectionCode catalogNumber
1 PreservedSpecimens Duckeodendron cestroides 3456-A - Oliveira -INPA.12345A INPA 12345A
2 PreservedSpecimens Duckeodendron cestroides 3456-A - Oliveira -MO.ANOTHER FAKE CODE MO ANOTHER FAKE CODE
3 PreservedSpecimens Duckeodendron cestroides 3456-A - Oliveira -NY.574635 NY 574635
Importar Vouchers para Indivíduos registrados
- Vouchers são amostras de Indivíduos depositados em BioColeções. Se a Biocoleção for um recurso genético, o Voucher pode representar apenas uma amostra de DNA ou tecido.
- Portanto, os Vouchers devem pertencer a um Indivíduo e à uma Biocoleção, que são as informações obrigatórias para o cadastro de Vouchers. Coletores, data de coleta, localização e identidade taxonômica podem simplesmente ser extraídos do cadastro do Indivíduo.
- O Voucher pode ter coletor, número de coletor e data de coleta próprios, distintos do Indivíduo a que pertence, quando necessário.
Os campos obrigatórios são:
individual= id do indivíduo ou nome completo (organismID);biocollection= sigla ou id da Biocoleção - useodb_get_biocollections()para verificar se está registrado, caso contrário, primeiro registre a Biocoleção no banco de dados;
Para campos adicionais veja Voucher POST API.
Uma importação de voucher simples
#a holotype voucher with same collector and date as individual
onevoucher = data.frame(individual=1,biocollection="INPA",biocollection_number=1234,biocollection_type=1,dataset=1)
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
odb_import_vouchers(onevoucher, odb_cfg=cfg)
#get the imported voucher
voucher = odb_get_vouchers(params=list(individual=1),cfg)
vouchers[,c("basisOfRecord","scientificName","occurrenceID","collectionCode","catalogNumber") ]
Voucher diferente para um indivíduo
Dois vouchers para o mesmo Indivíduo, um com o mesmo coletor e data de coleta do Indivíduo, outro em data diferente e por outros cobradores.
#one with same date and collector as individual
one = data.frame(individual=2,biocollection="INPA",biocollection_number=1234,dataset=1,collector=NA,number=NA,date=NA)
#this one with different collector and date
two= data.frame(individual=2,biocollection="INPA",biocollection_number=4435,dataset=1,collector="Oliveira, A.A. de|João Batista da Silva",number=3456,date="1991-08-01")
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
to.odb = rbind(one,two)
odb_import_vouchers(to.odb, odb_cfg=cfg)
#get the imported voucher
voucher = odb_get_vouchers(params=list(individual=2),cfg)
voucher[,c("basisOfRecord","scientificName","occurrenceID","collectionCode","catalogNumber") ]
Registros importados:
basisOfRecord scientificName occurrenceID collectionCode catalogNumber recordedByMain
1 PreservedSpecimens Unidentified plot tree - Vicentini -INPA.1234 INPA 1234 Vicentini, A.
2 PreservedSpecimens Unidentified 3456 - Oliveira -INPA.4435 INPA 4435 Oliveira, A.A. de
6.2.9 - Importar Medições
- A medição tem uma restrição: valores ou categorias de medição duplicados para o mesmo object_id e mesma data não serão importados, a menos que você especifique
duplicated = 1para o registro. - Para importar medições você precisa coletar algumas informações de outros modelos. Você precisa fornecer um
datasetpara o qual você tem permissões,trait_id(export_name ou id),value(o conteúdo varia dependendo do tipo de variável),date(uma data completa ou incompleta),person(pessoa que mediu),object_type(uma de taxon, individual, voucher ou location) eobject_id(o id do object_type). Para o tipo de variável LINK você deve fornecer uma colunalink_id, e ‘value’ torna-se opcional para este caso específico. - DICA: Para relacionar medições de diferentes variáveis, você pode adicionar palavaras chave campo de medição
notes. Por exemplo, você mede LeafLength e LeafWidth para as mesmas folhas, portanto, em ambas as medições, adicione “leaf1”, “leaf2” ao campo de nota para vinculá-los. Além disso, se você medir o DAP e o DAP.POM em um inventário de parcela florestal e se tiver vários troncos para uma planta, você pode adicionar “caule1”, “caule2” para permitir a correspondência de um DAP do caule com sua altura específica de medição. Esse tipo de link pode ser útil em análises. - Várias validações acontecerão durante a importação da medição. Considere verificar os dados localmente antes de enviar um trabalho (job) para facilitar a solução de problemas e garantir que os valores sejam consistentes com suas expectativas. Você não poderá ATUALIZAR nem EXCLUIR medidas com a API, portanto, evite importar medições que precisarão ser corrigidas posteriormente (uma por uma).
- Para características quantitativas, OpenDataBio não pode validar se suas medições estão na mesma unidade que a definição de variável. Portanto, verifique qual unidade a variável possui e converta seus dados de acordo antes de enviar.
As medições podem ser importadas usando odb_import_measurements(). Leia atentamente o Measurements POST API.
Variáveis Quantitativas
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#obter o id do trait do servidor (verifique se o trait existe)
#gerar alguns dados falsos para 10 medições
dbhs = sample(seq(10,100,by=0.1),10)
object_ids = sample(1:3,length(dbhs),replace=T)
dates = sample(as.Date("2000-01-01"):as.Date("2000-03-31"),length(dbhs))
dates = lapply(dates,as.Date,origin="1970-01-01")
dates = lapply(dates,as.character)
dates = unlist(dates)
to.odb = data.frame(
trait_id = 'dbh',
value = dbhs,
date = dates,
object_type = 'Individual',
object_id=object_ids,
person="Oliveira, A.A. de",
dataset = 1,
notes = "some fake measurements",
stringsAsFactors=F)
#isso só funcionará se a pessoa existir, os ids individuais existirem
#e se a característica com export_name = dbh existe
odb_import_measurements(to.odb,odb_cfg=cfg)
Baixar os dados importados:
dad = odb_get_measurements(params = list(dataset=1),odb_cfg=cfg)
dad[,c("id","basisOfRecord", "measured_type", "measured_id", "measurementType",
"measurementValue", "measurementUnit", "measurementDeterminedDate",
"datasetName", "license")]
id basisOfRecord measured_type measured_id measurementType measurementValue measurementUnit measurementDeterminedDate
1 1 MeasurementsOrFact App\\Models\\Individual 3 dbh 86.8 centimeters 2000-02-19
2 2 MeasurementsOrFact App\\Models\\Individual 2 dbh 84.8 centimeters 2000-03-25
3 3 MeasurementsOrFact App\\Models\\Individual 2 dbh 65.7 centimeters 2000-03-15
4 4 MeasurementsOrFact App\\Models\\Individual 3 dbh 88.0 centimeters 2000-03-05
5 5 MeasurementsOrFact App\\Models\\Individual 3 dbh 35.3 centimeters 2000-01-04
6 6 MeasurementsOrFact App\\Models\\Individual 2 dbh 36.0 centimeters 2000-03-23
7 7 MeasurementsOrFact App\\Models\\Individual 2 dbh 78.6 centimeters 2000-03-22
8 8 MeasurementsOrFact App\\Models\\Individual 2 dbh 69.7 centimeters 2000-03-09
9 9 MeasurementsOrFact App\\Models\\Individual 3 dbh 12.3 centimeters 2000-01-30
10 10 MeasurementsOrFact App\\Models\\Individual 3 dbh 14.7 centimeters 2000-01-18
datasetName license
1 Dataset test CC-BY 4.0
2 Dataset test CC-BY 4.0
3 Dataset test CC-BY 4.0
4 Dataset test CC-BY 4.0
5 Dataset test CC-BY 4.0
6 Dataset test CC-BY 4.0
7 Dataset test CC-BY 4.0
8 Dataset test CC-BY 4.0
9 Dataset test CC-BY 4.0
10 Dataset test CC-BY 4.0
Medidas categóricas
As categorias DEVEM ser informadas por seus ids ou nome no campo value. Para características CATEGORICAL ou ORDINAL, value deve ser um valor único. Para CATEGORICAL_MULTIPLE, value pode ser um ou vários ids de categorias ou nomes separados por um de | ou ; ou,.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#a categorical trait
(odbtraits = odb_get_traits(params=list(name="specimenFertility"),odb_cfg = cfg))
#base line
to.odb = data.frame(trait_id = odbtraits$id, date = '2021-07-31', stringsAsFactors=F)
#the plant was collected with both flowers and fruits, so the value are the two categories
value = c("Flowers","Fruits")
#get categories for this trait if found
(cats = odbtraits$categories[[1]])
#check that your categories are registered for the trait and get their ids
value = cats[match(value,cats$name),'id']
#make multiple categories ids a string value
value = paste(value,collapse=",")
to.odb$value = value
#this links to a voucher
to.odb$object_type = "Voucher"
#get voucher id from API (must be ID).
#Search for collection number 1234
odbspecs = odb_get_vouchers(params=list(number="3456-A"),odb_cfg=cfg)
to.odb$object_id = odbspecs$id[1]
#get dataset id
odbdatasets = odb_get_datasets(params=list(name='Dataset test'),odb_cfg=cfg)
head(odbdatasets)
to.odb$dataset = odbdatasets$id
#person that measured
odbperson = odb_get_persons(params=list(search='ana cristina sega'),odb_cfg=cfg)
to.odb$person = odbperson$id
#import'
odb_import_measurements(to.odb,odb_cfg=cfg)
#get imported
dad = odb_get_measurements(params = list(voucher=odbspecs$id[1]),odb_cfg=cfg)
dad[,c("id","basisOfRecord", "measured_type", "measured_id", "measurementType",
"measurementValue", "measurementUnit", "measurementDeterminedDate",
"datasetName", "license")]
id basisOfRecord measured_type measured_id measurementType measurementValue measurementUnit
1 11 MeasurementsOrFact App\\Models\\Voucher 1 specimenFertility Flowers, Fruits NA
measurementDeterminedDate datasetName license
1 2021-07-31 Dataset test CC-BY 4.0
Cores
Para valores de cor, você deve inserir cor como seus códigos de strings RGB hexadecimal, para que possam ser renderizados graficamente e na interface da web. Portanto, qualquer valor de cor é permitido e seria mais fácil usar as cores da paleta na interface da web para inserir tais medidas. O pacote gplots permite que você converta nomes de cores em códigos RGB hexadecimais se você quiser fazer isso por meio da API.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#get the trait id from the server (check that trait exists)
odbtraits = odb_get_traits(odb_cfg=cfg)
(m = match(c("fruitColor"),odbtraits$export_name))
#base line
to.odb = data.frame(trait_id = odbtraits$id[m], date = '2014-01-13', stringsAsFactors=F)
#get color value
#install.packages("gplots",dependencies = T)
library(gplots)
(value = col2hex("red"))
to.odb$value = value
#this links to a specimen
to.odb$object_type = "Individual"
#get voucher id from API (must be ID). Search for collection number 1234
odbind = odb_get_individuals(params=list(tag='3456'),odb_cfg=cfg)
odbind$scientificName
to.odb$object_id = odbind$id[1]
#get dataset id
odbdatasets = odb_get_datasets(params=list(name='Dataset test'),odb_cfg=cfg)
head(odbdatasets)
to.odb$dataset = odbdatasets$id
#person that measured
odbperson = odb_get_persons(params=list(search='ana cristina sega'),odb_cfg=cfg)
to.odb$person = odbperson$id
odb_import_measurements(to.odb,odb_cfg=cfg)

Medições de tipo de LINK de banco de dados
O tipo de variável LINK permite registrar dados de contagem, como por exemplo o número de indivíduos de uma espécie em um determinado local. Você deve fornecer o objeto vinculado (link_id), que pode ser um Táxon ou um Voucher, dependendo da definição da variável, e então o value recebe a contagem numérica.
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#get the trait id from the server (check that trait exists)
odbtraits = odb_get_traits(odb_cfg=cfg)
(m = match(c("taxonCount"),odbtraits$export_name))
#base line
to.odb = data.frame(trait_id = odbtraits$id[m], date = '2014-01-13', stringsAsFactors=F)
#the taxon to link the count value
odbtax = odb_get_taxons(params=list(name='Ocotea guianensis'),odb_cfg=cfg)
to.odb$link_id = odbtax$id
#now add the count value for this trait type
#this is optional for this measurement,
#however, it would make no sense to include such link without a count in this example
to.odb$value = 23
#a note to clarify the measurement (optional)
to.odb$notes = 'No voucher, field identification'
#this measurement will link to a location
to.odb$object_type = "Location"
#get location id from API (must be ID).
#lets add this to a transect
odblocs = odb_get_locations(params=list(adm_level=101,limit=1),odb_cfg=cfg)
to.odb$object_id = odblocs$id
#get dataset id
odbdatasets = odb_get_datasets(params=list(name='Dataset test'),odb_cfg=cfg)
head(odbdatasets)
to.odb$dataset = odbdatasets$id
#person that measured
odbperson = odb_get_persons(params=list(search='ana cristina sega'),odb_cfg=cfg)
to.odb$person = odbperson$id
odb_import_measurements(to.odb,odb_cfg=cfg)

Medições espectrais
value deve ser uma string de valores do espectro separados por “;”. O número de valores concatenados deve corresponder ao atributo value_length da variável, que é extraído da especificação do intervalo de número de onda para a variável. Portanto, você pode verificar isso facilmente antes de importar com odb_get_traits(params=list (fields = 'all', type = 9),cfg)
library(opendatabio)
base_url="https://opendb.inpa.gov.br/api"
token ="GZ1iXcmRvIFQ" #this must be your token not this value
cfg = odb_config(base_url=base_url, token = token)
#read a spectrum
spectrum = read.table("1_Sample_Planta-216736_TAG-924-1103-1_folha-1_abaxial_1.csv",sep=",")
#second column are NIR leaf absorbance values
#the spectrum has 1557 values
nrow(spectrum)
#[1] 1557
#collapse to single string
value = paste(spectrum[,2],collapse = ";")
substr(value,1,100)
#[1] "0.6768057;0.6763237;0.6755353;0.6746023;0.6733549;0.6718447;0.6701176;0.6682984;0.6662288;0.6636459;"
#get the trait id from the server (check that trait exists)
odbtraits = odb_get_traits(odb_cfg=cfg)
(m = match(c("driedLeafNirAbsorbance"),odbtraits$export_name))
#see the trait
odbtraits[m,c("export_name", "unit", "range_min", "range_max", "value_length")]
#export_name unit range_min range_max value_length
#6 driedLeafNirAbsorbance absorbance 3999.64 10001.03 1557
#must be true
odbtraits$value_length[m]==nrow(spectrum)
#[1] TRUE
#base line
to.odb = data.frame(trait_id = odbtraits$id[m], value=value, date = '2014-01-13', stringsAsFactors=F)
#this links to a voucher
to.odb$object_type = "Voucher"
#get voucher id from API (must be ID).
#search for a collection number
odbspecs = odb_get_vouchers(params=list(number="3456-A"),odb_cfg=cfg)
to.odb$object_id = odbspecs$id[1]
#get dataset id
odbdatasets = odb_get_datasets(params=list(name='Dataset test'),odb_cfg=cfg)
to.odb$dataset = odbdatasets$id
#person that measured
odbperson = odb_get_persons(params=list(search='adolpho ducke'),odb_cfg=cfg)
to.odb$person = odbperson$id
#import
odb_import_measurements(to.odb,odb_cfg=cfg)
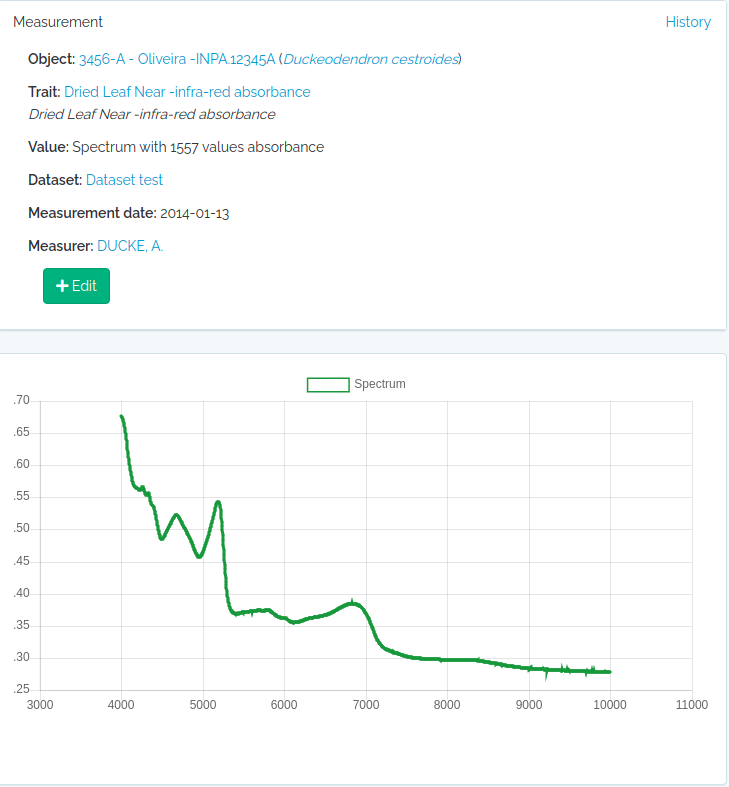
Texto e notas
Basta adicionar o texto ao campo value e proceder como para os outros tipos de variável.